BrowseAct Professional Workflow Guide

Node Configuration & Best Practices for Web Scraping Automation
🎯 What is BrowseAct Workflow?
BrowseAct is an intelligent web automation platform that combines AI-powered browser interaction with structured data extraction capabilities. It enables users to create sophisticated web scraping workflows without coding.
Core Purpose:
- Automate Complex Web Interactions: Navigate websites, fill forms, click elements, and extract data automatically
- AI-Driven Element Recognition: Uses computer vision to identify and interact with web elements dynamically
- Scalable Data Collection: Handle pagination, loops, and bulk data extraction efficiently
- No-Code Solution: Create powerful scraping workflows through visual node configuration
Key Advantages:
- ✅ Handles Dynamic Content: Works with JavaScript-heavy sites and lazy-loaded content
- ✅ Anti-Detection Technology: Mimics human behavior to avoid bot detection
- ✅ Visual Workflow Builder: Drag-and-drop interface for complex automation sequences
- ✅ Real-Time Adaptation: AI adjusts to website changes and layout variations
- ✅ Structured Output: Clean, formatted data ready for analysis
Professional Node Configuration Guide
Case Study: Amazon Women's Swimwear Data Extraction
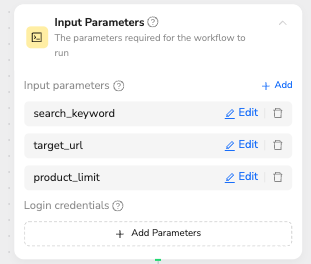
Node 0: Input Parameters
🎯 Node Capability: Define global variables and credentials for workflow execution
📝 Configuration Rules:
- Values should be descriptive and reusable across nodes
- Include authentication credentials if required
- Set realistic limits to prevent resource exhaustion
✅ Professional Prompt Template:
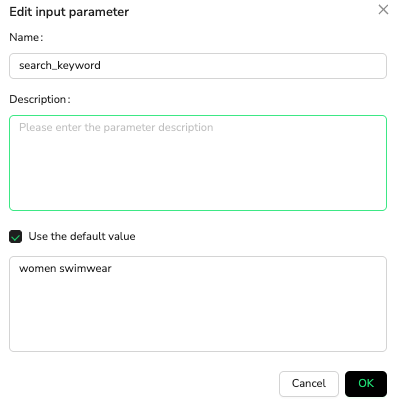
Input Variables:search_keyword = "women swimwear"target_url = "https://www.amazon.com/Best-Sellers-Clothing-Shoes-Jewelry-Womens-Swimwear/zgbs/fashion/1044956"product_limit = 20Optional: Login credentials can be added here if authentication is required
💡 Variable Reference: Use manual input or reference with /variable_name syntax
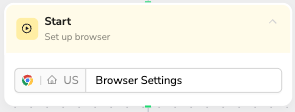
Node 1: Start (Browser Settings)
🎯 Node Capability: Configure browser environment and network settings for optimal scraping
📝 Configuration Rules:
- Browser Selection: Choose browser type (Chromium recommended for stability)
- Region Settings: Select geographic region to match the target website's expected audience
- IP Type Configuration: Choose between Residential or Datacenter IPs based on anti-detection needs
- Purpose: Establish proper browsing context before workflow execution
✅ Professional Configuration Template:
Browser Settings Configuration:
- Browser: Chromium (recommended for stability and compatibility)
- Region: USA (or target website's primary market)
- IP Type: Residential (for enhanced anti-detection)
Geographic Targeting:
- Use region matching your target website's main audience
- USA for Amazon.com, UK for Amazon.co.uk, etc.
- Ensures proper currency, language, and content display
IP Type Selection:
✅ Residential IP:
- Mimics real user behavior
- Lower detection risk
- Recommended for e-commerce sites
- Better for high-volume scraping
⚠️ Datacenter IP:
- Faster connection speeds
- More cost-effective
- Higher detection risk
- Suitable for internal tools or APIs
💡 Best Practice: Always match region settings with your target website's primary market for consistent results
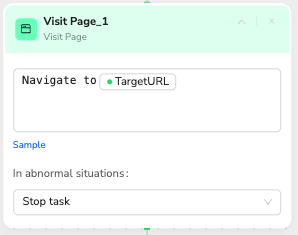
Node 2: Visit Page
🎯 Node Capability: Navigate to target URLs with intelligent loading verification
📝 Configuration Rules:
- Reference variables using
/variable_nameor manual URL input - Handle common popups and redirects automatically
✅ Professional Prompt Template:
Navigate to /target_url
💡 Alternative Manual Input: Direct URL entry without variable reference
Node 3: Wait
🎯 Node Capability: While all BrowseAct Workflow nodes inherently include intelligent waiting to ensure dynamic content loads and page stability, this dedicated "Wait" node provides explicit control for situations where the automated waiting might not be sufficient. It allows you to set a fixed duration for waiting, which is particularly useful for highly dynamic content, AJAX-loaded elements, or pages with unpredictable loading patterns.
📝 Configuration Rules:
- Set duration based on specific website loading behaviors.
- Primarily used when the built-in intelligent waiting of other nodes doesn't adequately handle dynamic content (e.g., dynamic pricing, lazy-loaded images, complex interactive elements).
- Balance between workflow execution speed and data reliability.
- Typical recommended range for fixed waits: 3-15 seconds.
Note: This is an optional node. Most scenarios will be handled by the intelligent waiting built into other nodes. Only use the "Wait" node if you observe inconsistent or incomplete data extraction due to specific page loading delays.
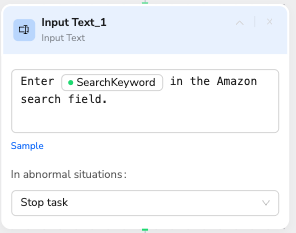
Node 4: Input Text
🎯 Node Capability: Smart text input with natural typing simulation
📝 Configuration Rules:
- Reference search variables with
/variable_nameor input manually - AI automatically locates input fields
- Handles autocomplete and suggestions
- Mimics human typing patterns
✅ Professional Prompt Template:
Enter /search_keyword in the Amazon search field.
💡 Manual Alternative: Enter "women swimwear" in the Amazon search field.
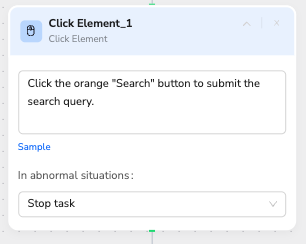
Node 5: Click Element
🎯 Node Capability: Precise element identification and interaction
📝 Configuration Rules:
- Describe elements by visual characteristics (color, text, position)
- AI uses computer vision for element recognition
- Include expected post-click behavior
- Handle dynamic button states
✅ Professional Prompt Template:
Click the orange "Search" button to submit the search query.
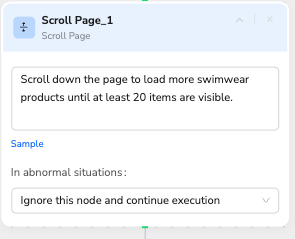
Node 6: Scroll Page
🎯 Node Capability: Intelligent scrolling with content loading detection
📝 Configuration Rules:
- Define clear stopping conditions
- Enable lazy-loaded content visibility
- Set maximum scroll limits to prevent infinite loops
- Monitor for new content appearance
✅ Professional Prompt Template:
Scroll down the page to load more swimwear products until at least 20 items are visible.
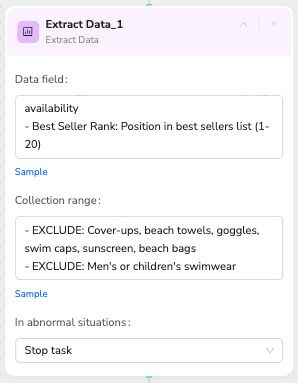
Node 7: Extract Data
🎯 Node Capability: Advanced data extraction with AI-powered field recognition
📝 Configuration Rules:
- Extraction Scope:
- Full Page Coverage: Extracts data from the entire webpage, including content outside the visible area
- Loaded Content Only: Cannot extract lazy-loaded or async content until it's loaded into the DOM
- Pre-loading Required: Use Scroll Page or other nodes to load content before extraction
- List specific fields to extract with clear descriptions
- Include inclusion/exclusion criteria for data filtering
- Handle missing data gracefully
- Maintain data consistency across extractions
✅ Professional Prompt Template:
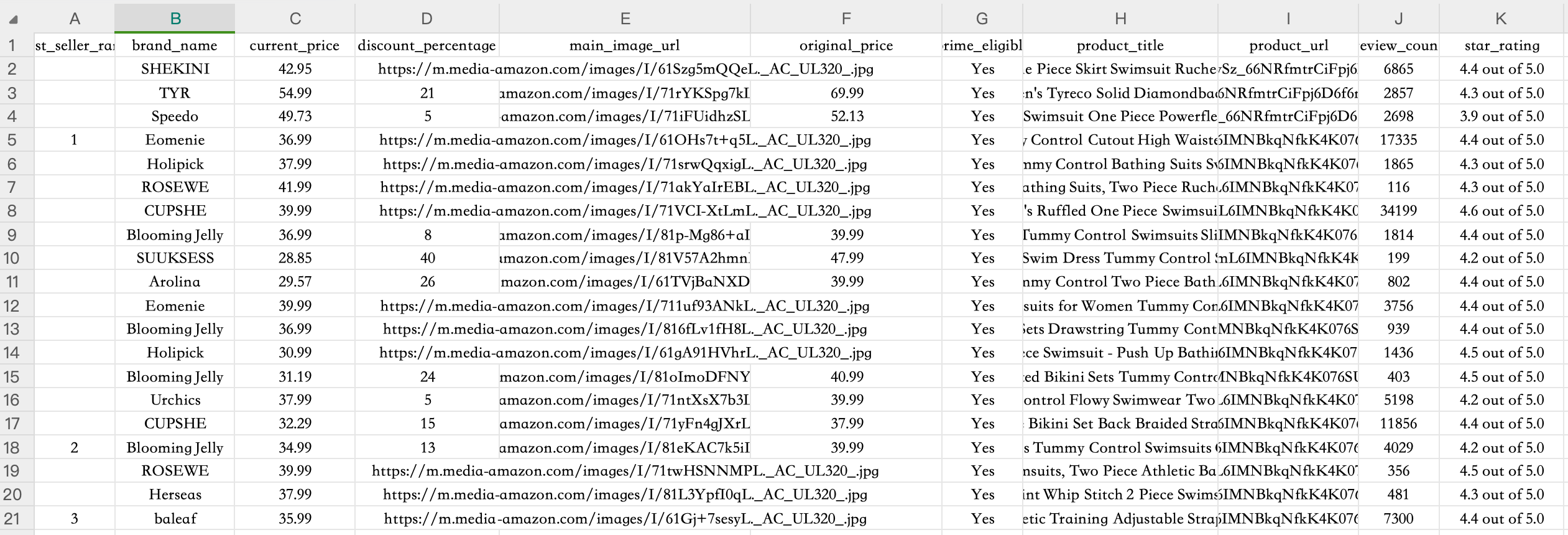
Data Fields to Extract:- Product Title: Complete product name including brand and style- Brand Name: Extract manufacturer/brand (e.g., "Speedo", "TYR")- Current Price: Displayed price in USD (remove $ symbol, numbers only)- Original Price: Original price if item is discounted- Discount Percentage: Calculate discount if applicable- Star Rating: Customer rating (format: X.X out of 5.0)- Review Count: Total number of customer reviews (numbers only)- Product URL: Complete product detail page link- Main Image URL: Primary product image source- Prime Eligible: Yes/No based on Prime shipping availability- Best Seller Rank: Position in best sellers list (1-20)Collection Criteria:INCLUDE: Bikinis, one-piece swimsuits, tankinis, swim dresses, competitive swimwearEXCLUDE: Cover-ups, beach towels, goggles, swim caps, sunscreen, beach bagsEXCLUDE: Men's or children's swimwear
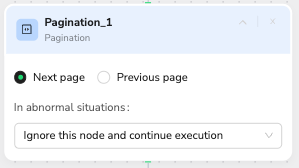
Node 8: Pagination
🎯 Node Capability: Navigate between pages by clicking pagination controls
📝 Configuration Rules:
- Core Function: Pure navigation - clicks pagination buttons to move between pages
- Navigation Methods: Supports "Next page" and "Previous page" buttons
- Smart Detection: Auto-identifies pagination elements and available page options
- Boundary Recognition: Detects when no more pages are available to prevent infinite navigation
- Note: This node only handles page navigation - combine with Extract Data nodes for data collection
✅ Professional Prompt Template:
Navigate to the next page of search results.
Look for the "Next" button, page numbers, or arrow navigation controls at the bottom of the page.
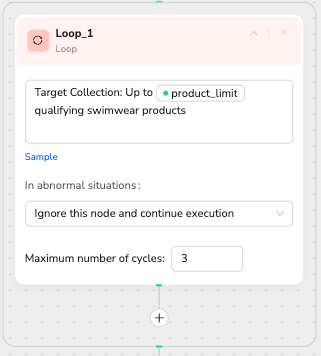
Node 9: Loop
🎯 Node Capability: Controlled iteration with intelligent exit conditions
📝 Configuration Rules:
- Set target collection goals using variables or manual limits
- Define maximum iterations to prevent infinite loops
- Include progress tracking and exit strategies
- Balance thoroughness with resource efficiency
✅ Professional Prompt Template:
Target Collection: Up to /product_limit qualifying productsMaximum Iterations: 3
💡 Manual Alternative: Target Collection: Up to 20 qualifying products
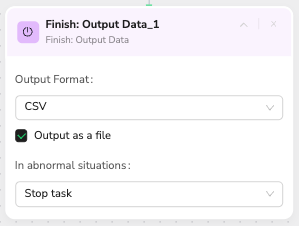
Node 10: Finish - Output Data
🎯 Node Capability: Professional data formatting and export with quality assurance
📝 Configuration Rules:
- Select appropriate output format (CSV, JSON)
- Enable the "Output as file" option for downloadable results
- Include data validation and cleaning steps
- Generate comprehensive export summaries
Test Your Workflow
After completing the workflow configuration, click on the "Test" navigation bar on the left to check if your workflow runs correctly. This crucial step allows you to:
- Observe the workflow's execution in real-time.
- Verify that each node performs its intended action.
- Identify and troubleshoot any immediate issues or unexpected behaviors.
- Confirm data extraction is proceeding as expected on a small scale.
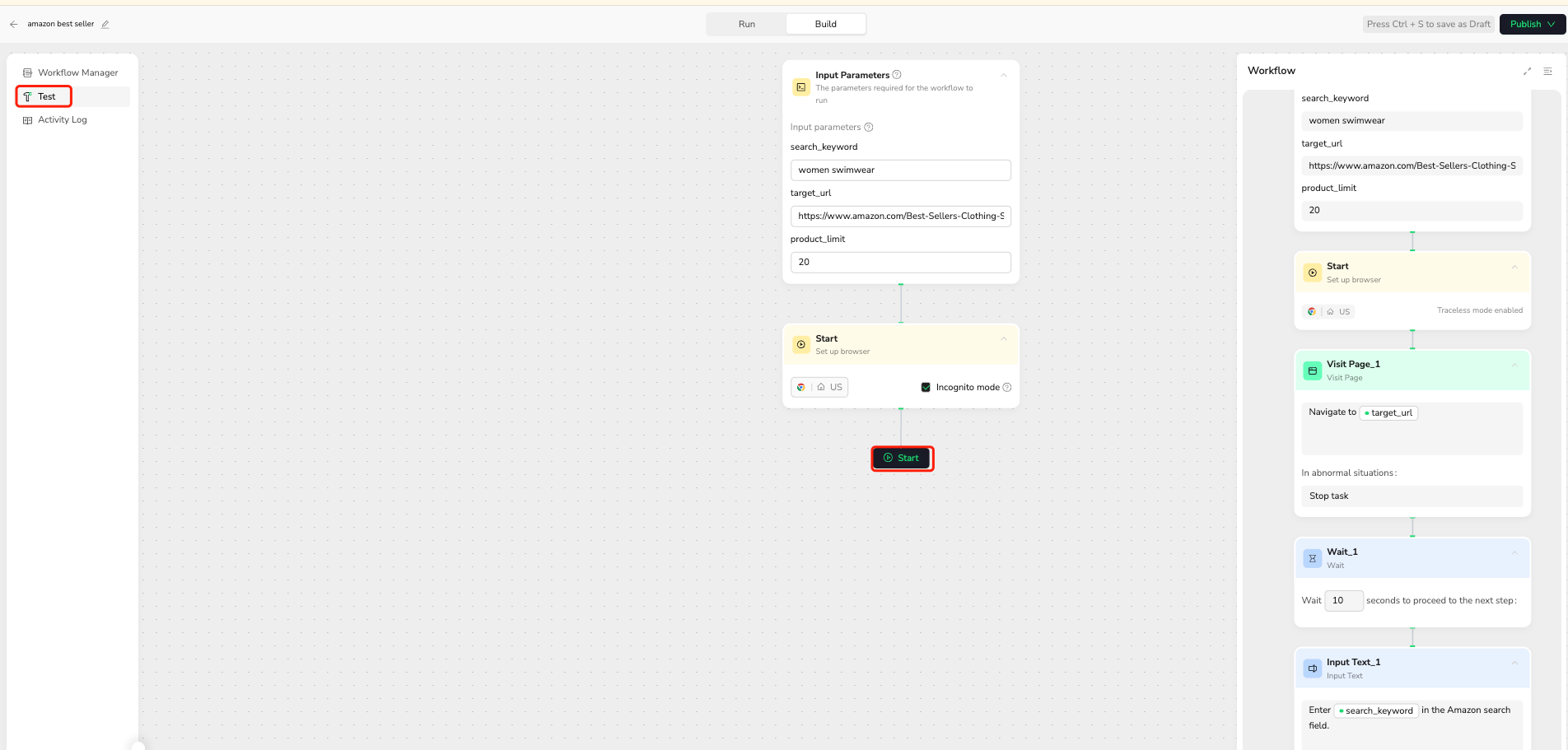
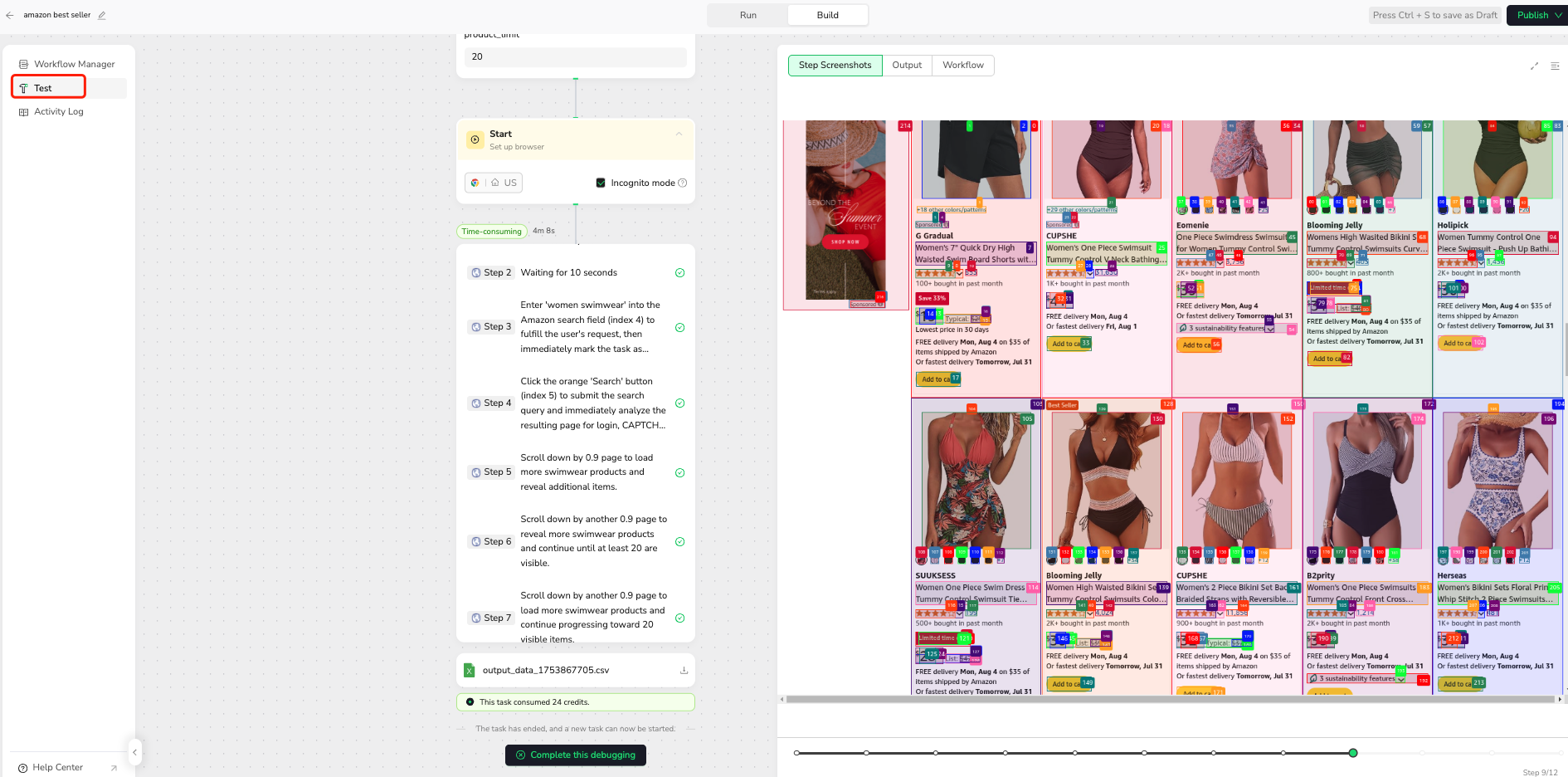
🚀 Workflow Execution
Publishing Your Workflow
Once you have configured all nodes according to the professional guidelines above and successfully tested your workflow, follow these steps to deploy your automation:
Step 1: Publish Workflow
Click the "Publish" button to finalize your workflow creation. This action:
- Validates your entire workflow configuration.
- Saves the workflow to your BrowseAct dashboard.
- Makes it available for execution.
- Creates a permanent workflow version for future use.

Executing Your Workflow
Step 2: Cost-Effective Automation
Click "Run" to start your automated workflow execution. This initiates the scraping process, allowing you to:
- Collect the desired data efficiently.
- Benefit from BrowseAct's cost advantages.
- Monitor the progress and access the results on your dashboard.
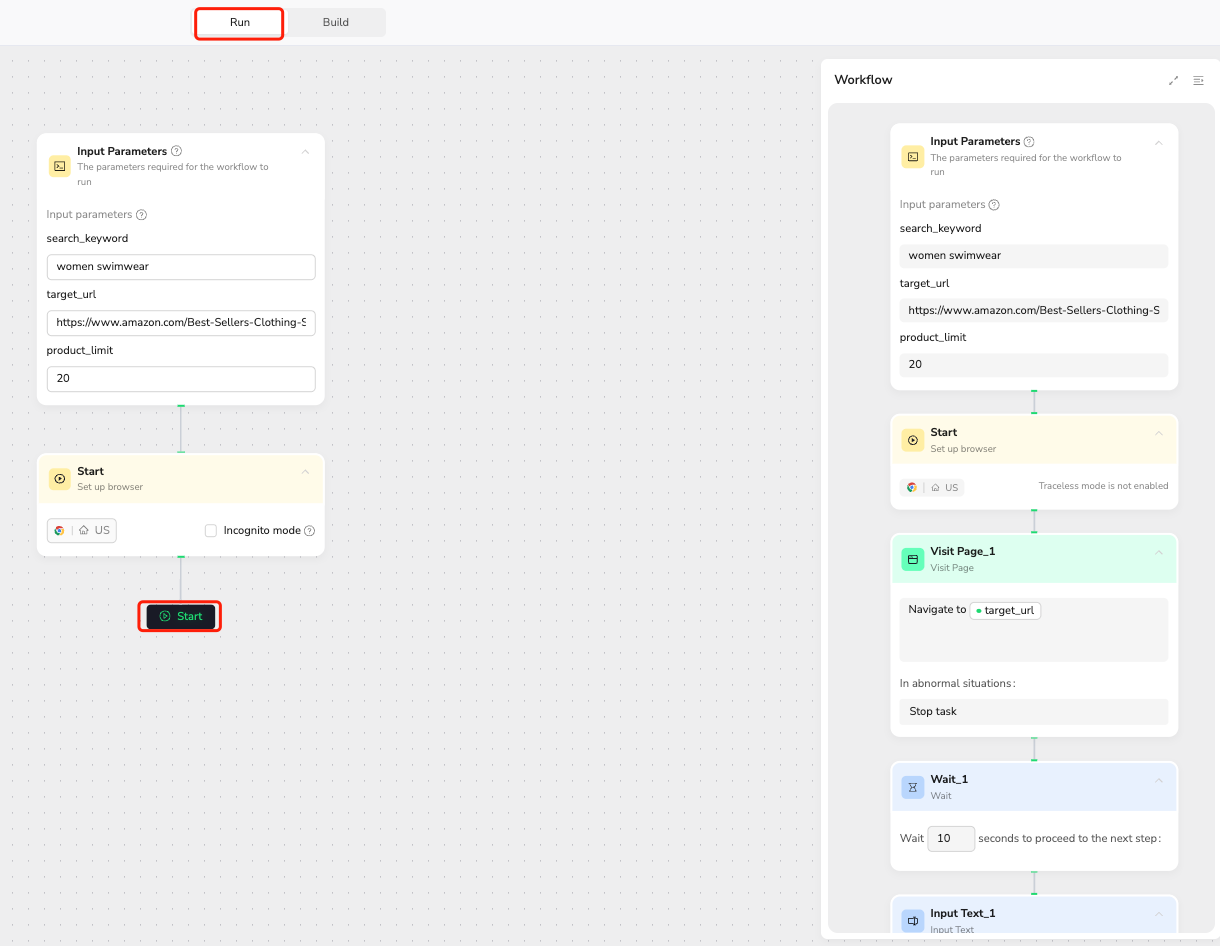
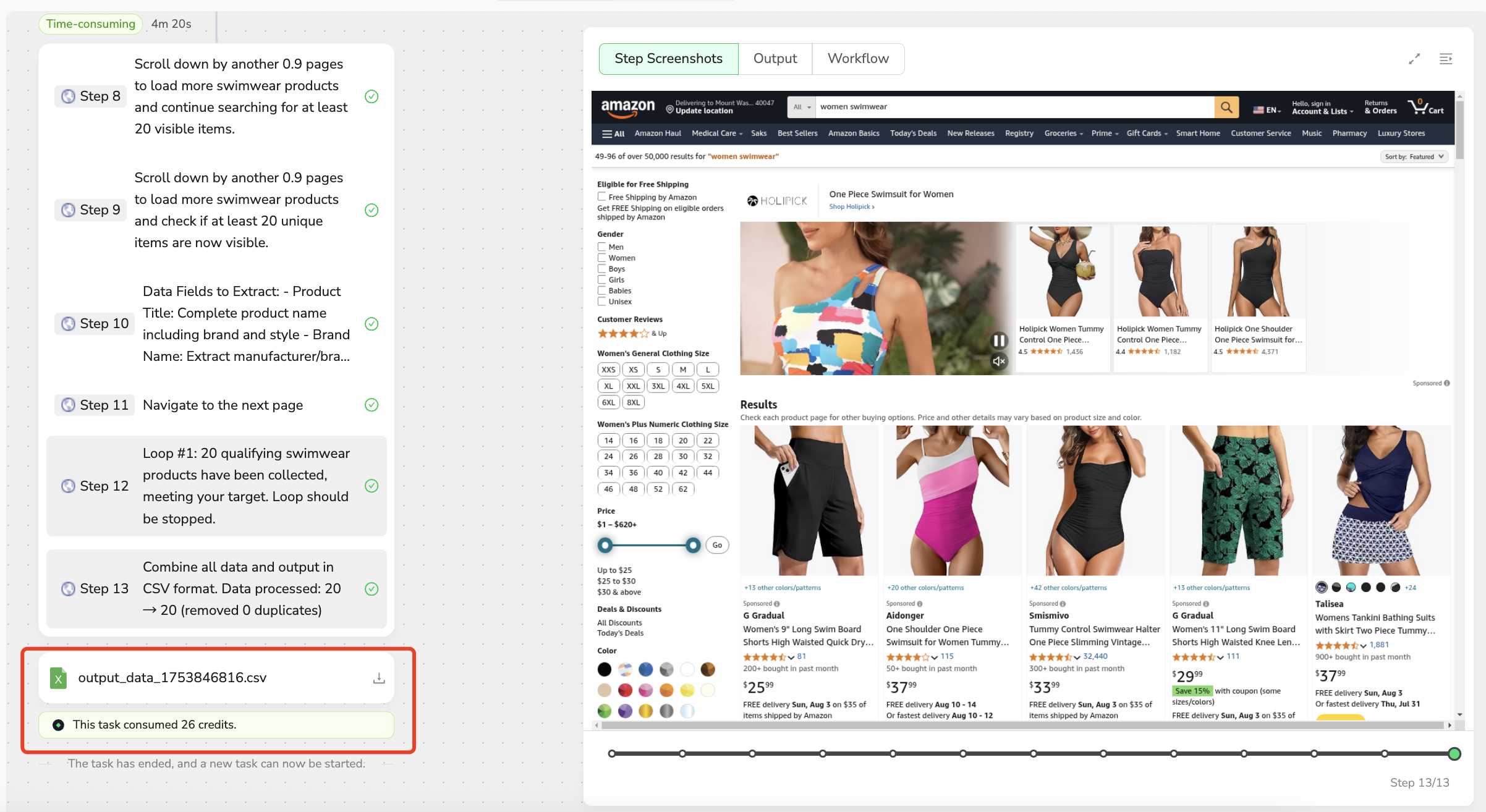
This streamlined deployment process transforms complex web scraping tasks into simple, cost-effective automation that delivers professional-grade results with minimal technical overhead.

Relative Resources




Latest Resources

BrowserAct vs Skyvern: Open-Source Browser Agent vs Managed Workflow

BrowserAct vs Selenium in 2026: Is It Time to Move On?

BrowserAct CAPTCHA Handling vs 2Captcha vs CapSolver: Real Cost Comparison
