BrowseAct Workflow is Now Live! More Accurate Data, Lower Costs!

BrowseAct Workflow: zero‑code, AI‑powered web scraping. Drag‑and‑drop nodes, natural‑language actions, smart fault tolerance & 90 % lower cost than agents.
🚀 Major Launch: BrowseAct Workflow Now Available
Breaking Traditional Boundaries, Redefining Web Scraping
BrowseAct Workflow is a revolutionary visual web scraping platform that combines intuitive, easy-to-understand nodes with natural language descriptions. Build personalized data extraction workflows without worrying about complex exception handling or technical configurations.
🎯 Core Advantages
- 🚫 No Coding Required - Zero-code threshold with visual node building
- 🎯 Precise Extraction - More accurate data extraction than AI Agents
- 🧠 Smart Recognition - More intelligent page understanding than traditional RPA
- 💰 Cost Advantage - 90% lower costs compared to Agent-based scraping
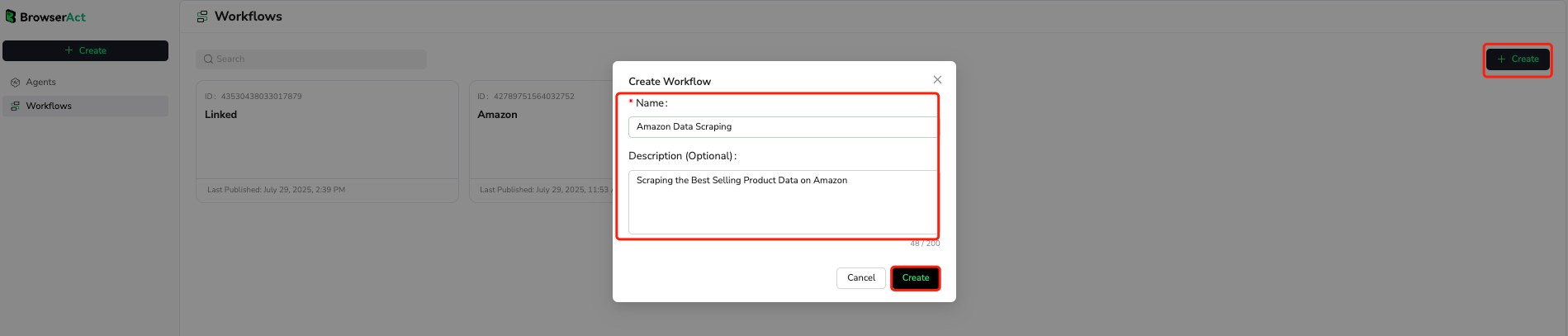
Getting Started with BrowseAct Workflow
Step 1: Quick Setup
- Log in to BrowseAct Platform
- Visit the BrowseAct website and register/log in to your account
- Select the "Workflow" module
- Creating a New Workflow
- Click the "Create " button
- Enter workflow name (e.g.,
Amazon Data Scraping) - Click "Create" to enter the visual editor
Complete Node Action Library Guide
BrowseAct provides a comprehensive node operation library where each node supports natural language descriptions, letting you focus on business logic rather than technical details:
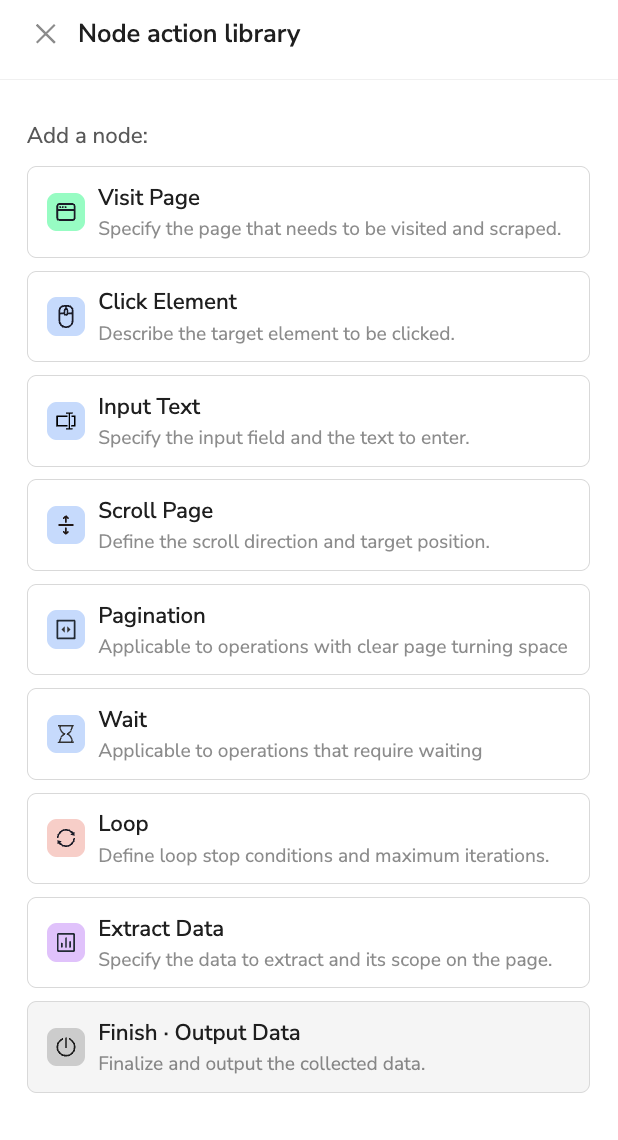
Notice: All nodes, including input, click, pagination, and scroll, are limited to elements contained within the current page.
📋 Input Parameters
Description: Define parameter variables required for workflow execution
- Use Cases: Search keywords, target URLs, login credentials
- Smart Features: Parameter reuse and automatic type recognition
- Configuration Example:
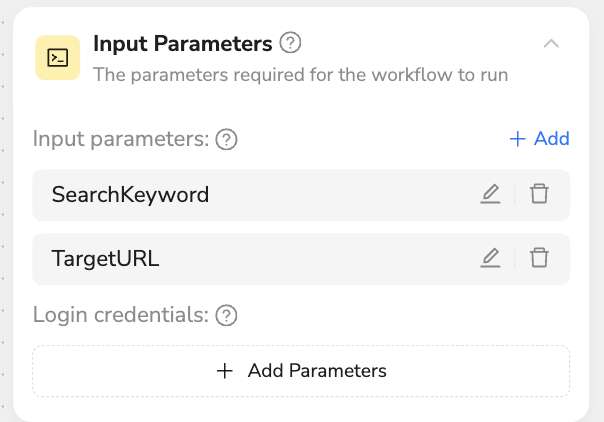
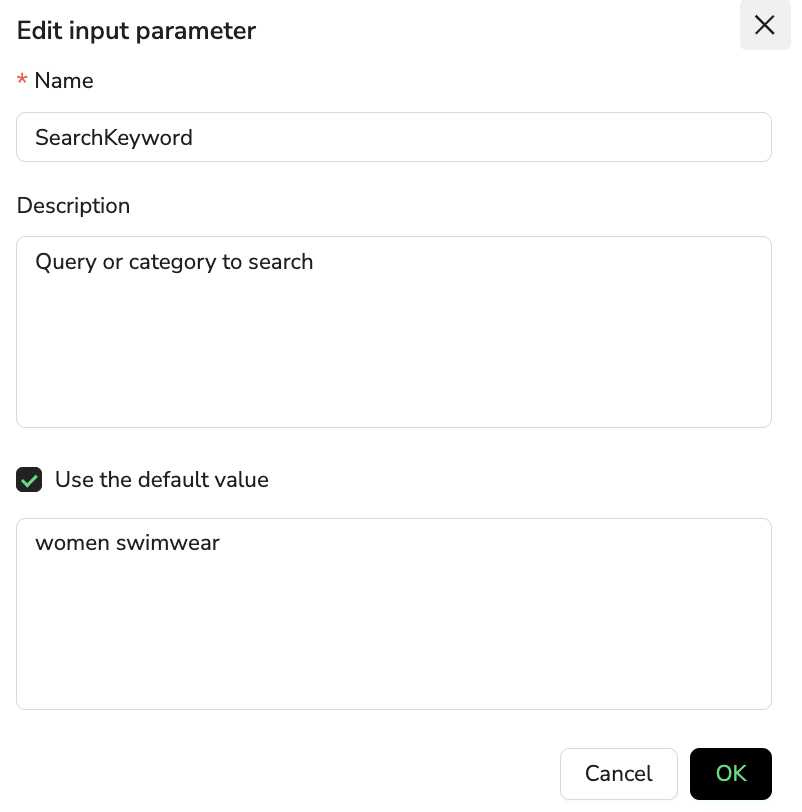
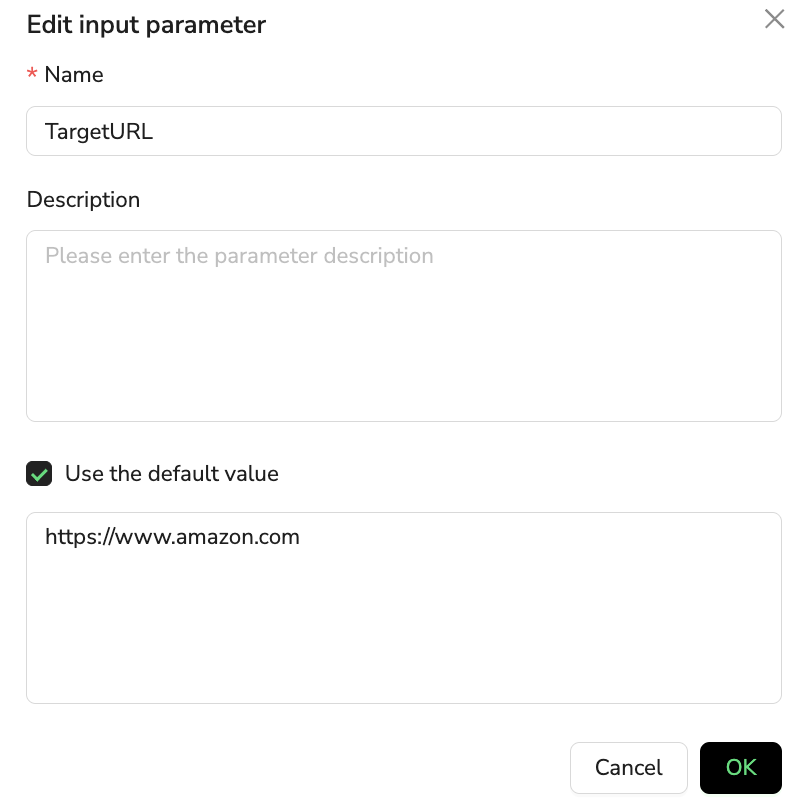
SearchKeyword: women swimwearTargetURL: https://www.amazon.com/best-sellers/...
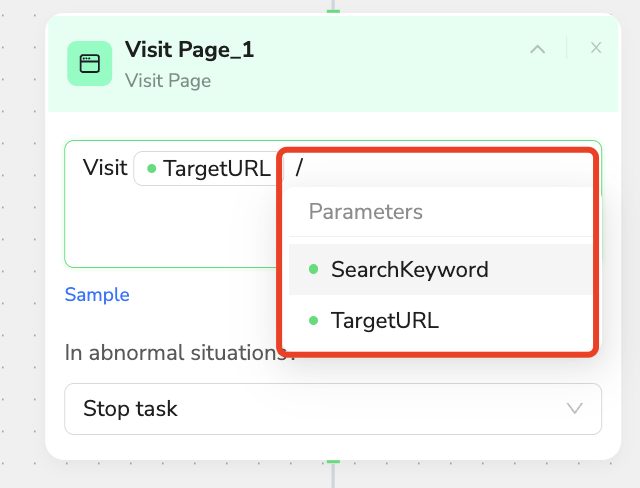
🌐 Visit Page
Description: Intelligently navigate to specified webpage and wait for complete loading
- Natural Language:
Visit {{TargetURL}} and wait for page to fully loador type "/" to select parameters - Smart Features: Automatically handles region selection and cookie popups
- Exception Handling: Auto-retry when page loading fails
- Best Practice: Built-in page integrity verification
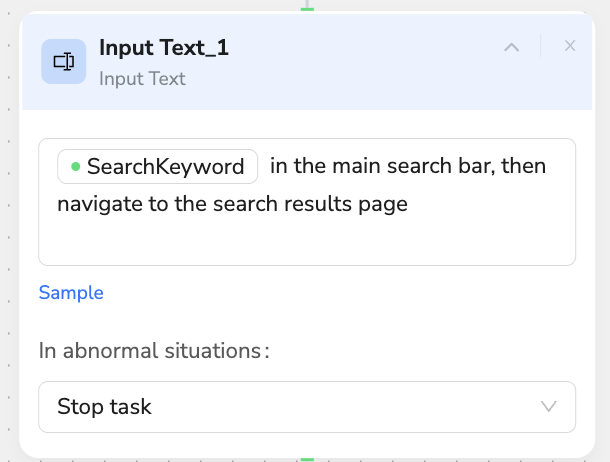
⌨️ Input Text
Description: Intelligently input text content into page input fields
- Natural Language:
Enter "SearchKeyword" in search box or type "/" to select parameters - Smart Features: Auto-detect input fields and clear existing content
- Use Cases: Search queries, form filling, filter conditions
- Human-like Design: Simulates realistic user typing speed
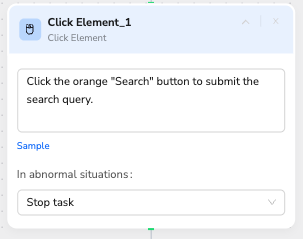
🖱️ Click Element
Description: Intelligently identify and click page elements
- Natural Language:
Click orange search button to submit searchorPress search icon to execute search - Smart Recognition: Auto-locate elements based on color, text, and position
- Exception Handling: Intelligent handling when elements are not visible
- Fault Tolerance: Supports multiple alternative positioning method
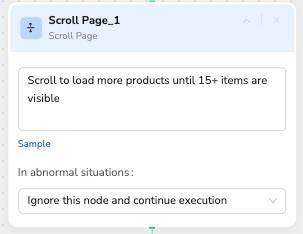
📜 Scroll Page
Description: Intelligently scroll pages to trigger data loading and expand AI's visual understanding area
- Primary Functions:
- Load More Data: Triggers lazy-loaded content and infinite scroll mechanisms
- Expand Visibility: Brings hidden elements into the viewport for AI recognition
- Natural Language:
Scroll to load more products until 15+ items are visibleorScroll down to product grid bottom section - Smart Control: Automatically detects page loading status and viewport changes
- AI Enhancement: Critical for AI page understanding as it relies on visible content area
- Use Cases: Control scroll pages, lazy-loaded content, bringing target elements into view
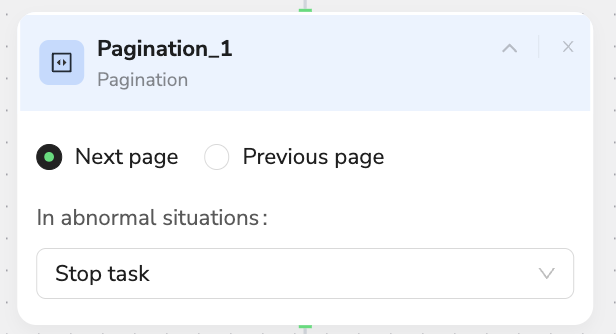
📄 Pagination
Description: Navigate between pages by clicking pagination controls
- Core Function: Pure navigation - clicks pagination buttons to move between pages
- Navigation Methods: Supports "Next page" and "Previous page" buttons
- Smart Detection: Auto-identifies pagination elements and available page options
- Boundary Recognition: Detects when no more pages are available to prevent infinite navigation
- Note: This node only handles page navigation - combine with Extract Data nodes for data collection
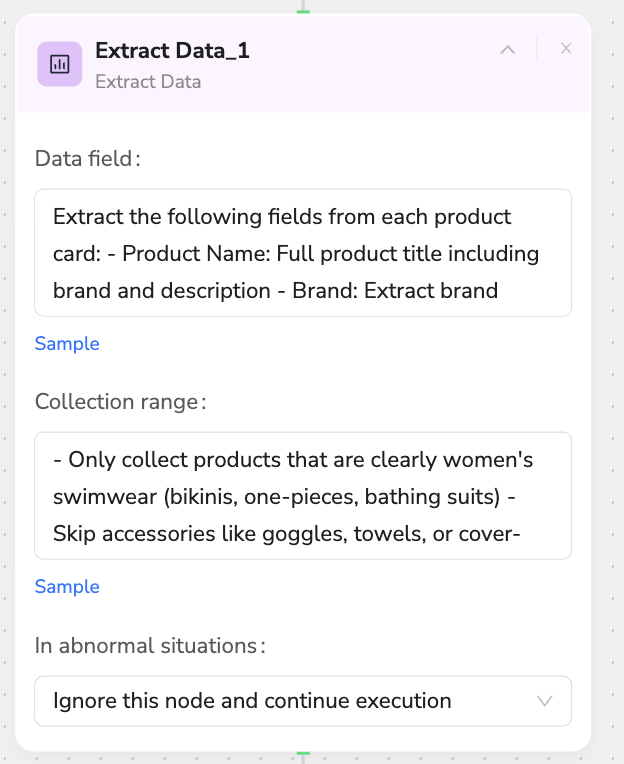
📊 Extract Data
Description: Core node for extracting structured data from entire web pages
- Extraction Scope:
- Full Page Coverage: Extracts data from the entire webpage, including content outside the visible area
- Loaded Content Only: Cannot extract lazy-loaded or async content until it's loaded into the DOM
- Pre-loading Required: Use Scroll Page or other nodes to load content before extraction
- Data Field Definition:
Extract the following fields from each product card:
- Product Name: Full product title including brand and description
- Brand: Extract brand name
- Collection Range Control:
Only collect products that are clearly women's swimwear (bikinis, one-pieces, bathing suits)
Skip accessories like goggles, towels, or cover-ups
- Data Processing Features:
- Format Conversion: Transform data formats (e.g., convert relative time to absolute time)
- Smart Recognition: Automatically identifies product types and filters irrelevant items
- Data Validation: Ensures accuracy and completeness of extracted data
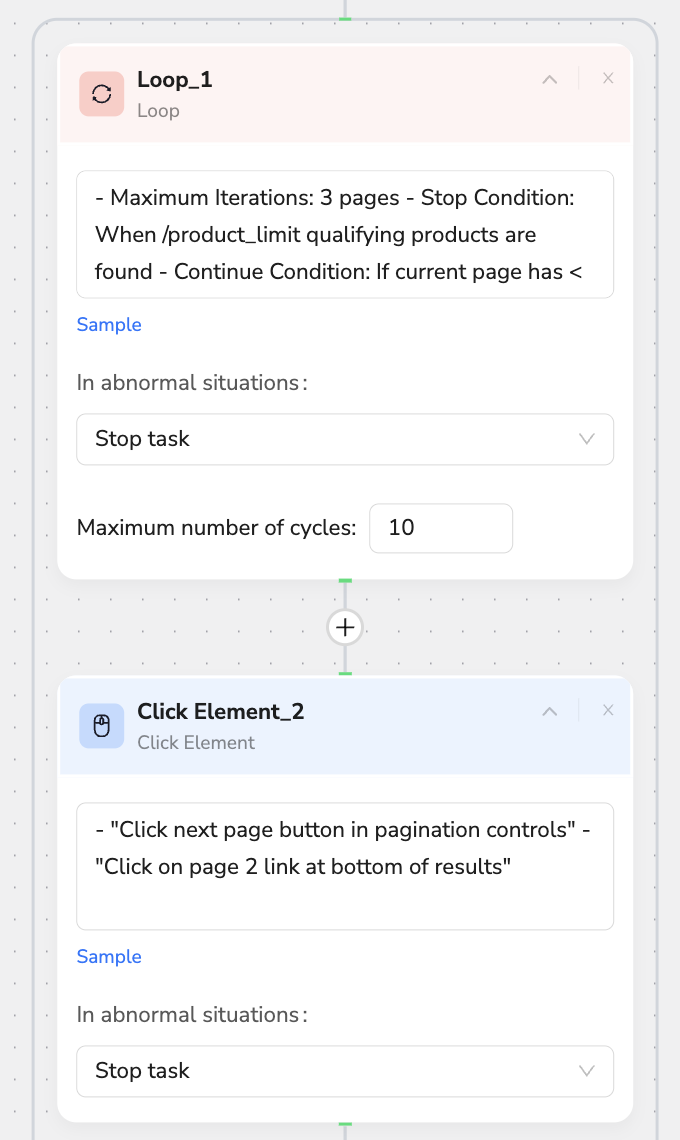
🔄 Loop
Description: Repeatedly execute a defined sub-workflow within the loop container
- Core Function:
- Sub-workflow Execution: Runs the workflow steps defined inside the loop node repeatedly
- Container Logic: All nodes placed within the loop will be executed in each iteration
- Loop Control:
Maximum Iterations: 3 pages
Stop Condition: When /product_limit qualifying products are found
Continue Condition: If current page has < target quantity, continue
- Smart Decision Making: Dynamically adjusts loop strategy based on page content and defined conditions
- Performance Optimization: Prevents ineffective loops and improves scraping efficiency by monitoring execution results
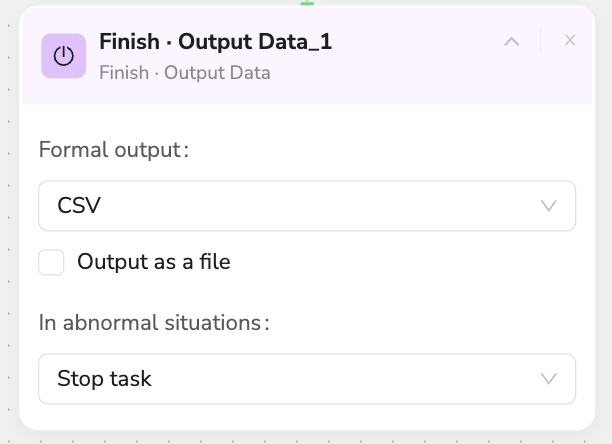
💾 Finish - Output Data
Description: Organize and output final scraping results
- Data Formatting: Auto-cleaning, deduplication, and sorting
- Output Options: Multiple format support including CSV, JSON
- File Naming: Smart timestamp naming rules
- Quality Assurance: Final data integrity verification
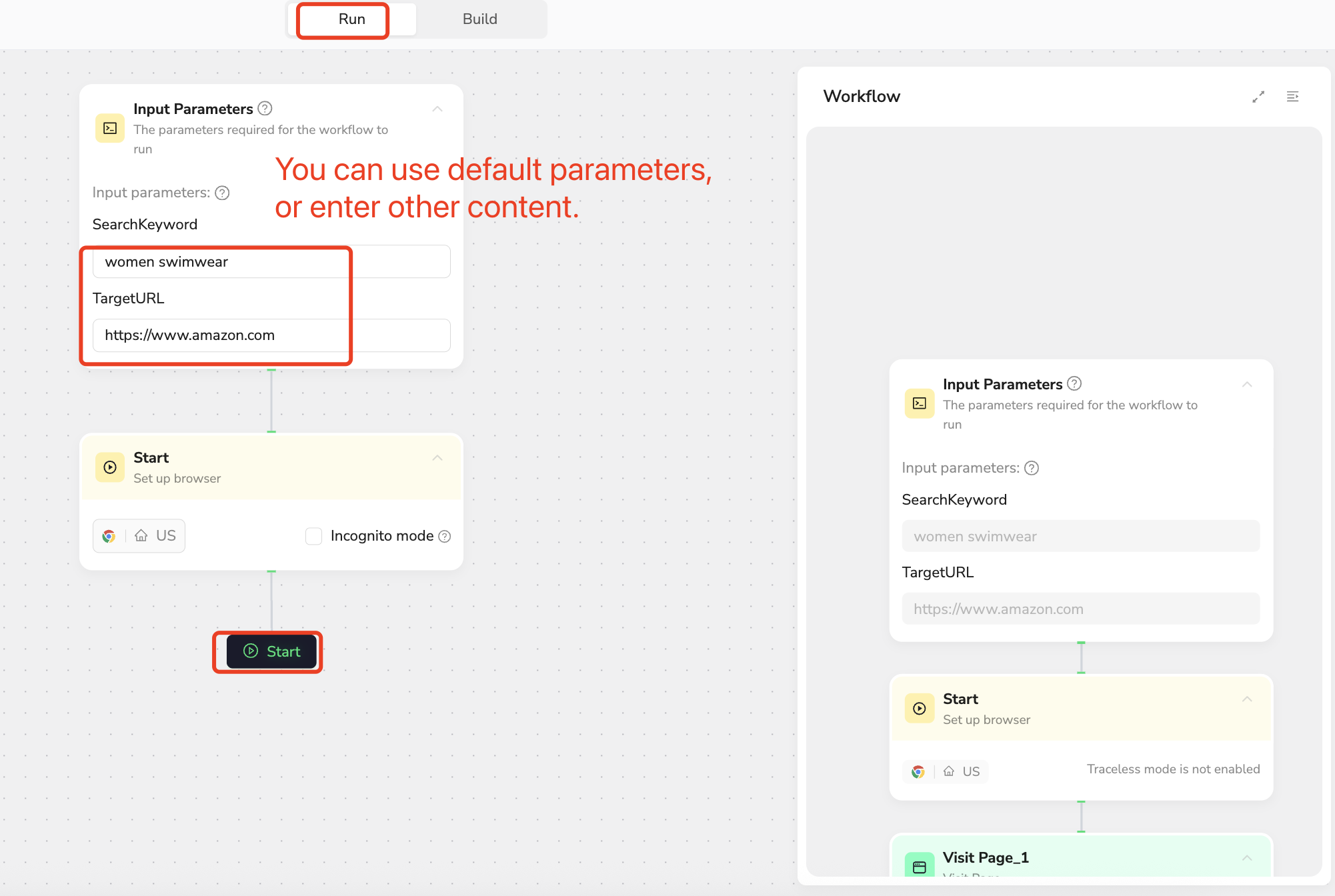
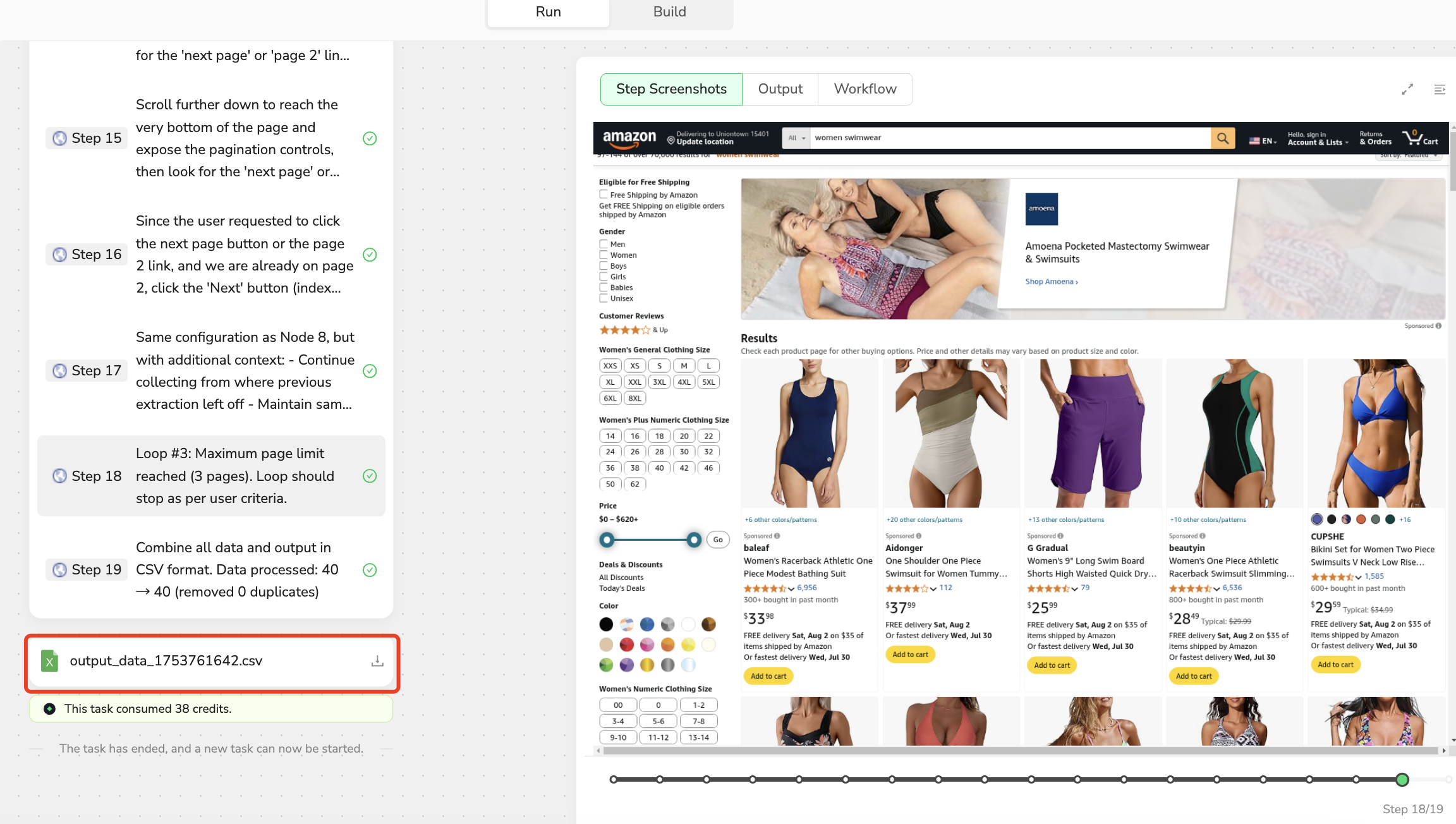
Test Your Workflow
After completing the workflow creation, click Publish to create the workflow successfully.
Running the Workflow: Click Run, then click Start to begin running the workflow and start scraping the data you want.

🌟 Revolutionary Advantages of BrowseAct Workflow
1. Natural Language-Driven Smart Operations
- Eliminate Complex Configurations: Describe operation intentions in natural language
- Intelligent Understanding: AI automatically converts descriptions into precise page operations
- Intuitive and Clear: Business users can easily understand and modify workflows
2. Zero Exception Handling Burden
- Built-in Smart Fault Tolerance: System automatically handles common exception scenarios
- Multiple Backup Solutions: Single nodes support multiple operation methods
- Graceful Degradation: Intelligent handling strategies when critical steps fail
3. Cost-Effectiveness Breakthrough
- Compared to Agent Scraping: 90% cost reduction
- Compared to Traditional RPA: 80% configuration time reduction
- Maintenance Costs: Nearly zero maintenance with adaptive page changes
4. Precision and Intelligence Combined
- More Accurate than Agents: Professional data extraction algorithms
- Smarter than RPA: AI-driven page understanding capabilities
- Adaptive Ability: Auto-adaptation when page structures change
Quick Start Guide
Create Your First Workflow in 5 Minutes
- Create Workflow - Start with a blank workflow
- Set Parameters - Configure parameter variables, or delete parameter settings for more flexible data searching
- Add Nodes - Click the plus sign below nodes to add new nodes
- Natural Language Description - Describe each node's operation in simple language
- One-Click Run - Click the run button to see scraping results
- Data Export - Automatically generate structured data files
Experience BrowseAct Workflow Today
🎉 Start Your Zero-Code Data Scraping Journey Now!
- 📈 Boost Efficiency: Projects that traditionally take weeks now complete in hours
- 💰 Reduce Costs: No need for professional development teams - business users can operate directly
- 🎯 Reliable and Accurate: AI-powered smart scraping with over 95% accuracy rate
- 🚀 Rapid Iteration: Adjust workflows in minutes when requirements change
Register now to experience the new era of intelligent data scraping!

Relative Resources




Latest Resources

BrowserAct vs Skyvern: Open-Source Browser Agent vs Managed Workflow

BrowserAct vs Selenium in 2026: Is It Time to Move On?

BrowserAct CAPTCHA Handling vs 2Captcha vs CapSolver: Real Cost Comparison
