BrowserAct Loop List Node—Beginner's Guide

Master BrowserAct's Loop List node for visible region list traversal, nested extraction, and dynamic adaptation. Ideal for Reddit posts, Amazon products, and job scraping. Learn features, rules, and real-world examples to streamline automation workflows and boost data collection efficiency.
What is the Loop List Node?
The Loop List Node helps you automatically go through items in a list on a web page—like job postings, product listings, or forum posts—and collect information from each one. It's designed for workflows where you want to extract data from lists without having to click each item by hand.
When Should You Use It?
Use the Loop List Node if you need to:
· Scrape data from lists that load dynamically (like "infinite scroll" or with a "Load More" button)
· Extract details from each item in a list (for example, each Reddit post’s title, author, and comments)
· Navigate to secondary/detail pages for each item and extract more data
How to Set Up a Loop List Node (Step by Step)
1.Insert the Node
Click the + button in your workflow, then select "Loop List Node" from the node library.
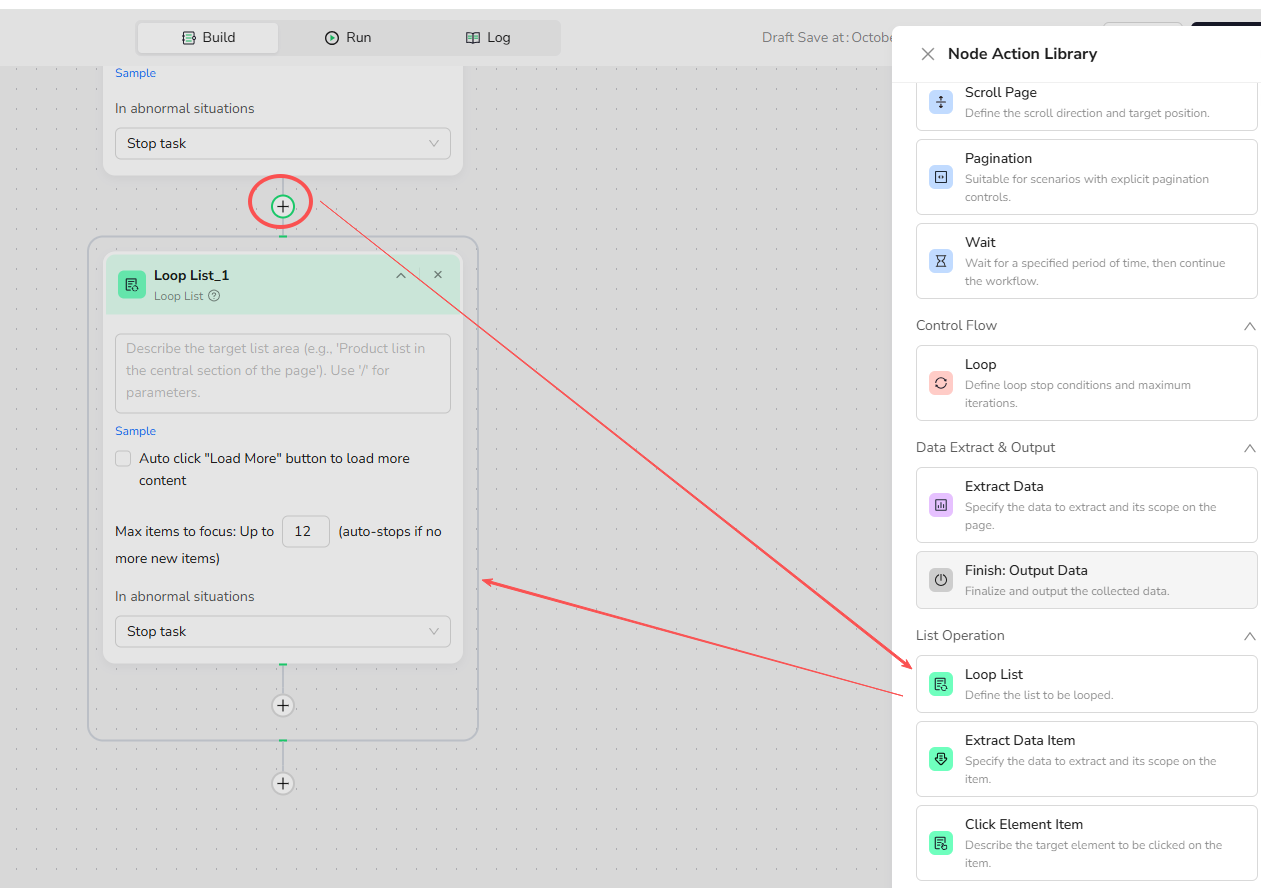
2.Complete the basic Loop List settings:
- List Region Description: Define the target area, e.g., "Job listings in the middle section of the page."
- Load More: Check only if the page has a "Load More" button or pagination; this automates scrolling or clicking to fetch additional items.
- Max Focused Loop Items: Set the maximum number of iterations. Defaults to 10, with a maximum of 999. The loop exits when the set number is reached. Adjust based on page content:
3.Add Sub-Nodes Inside the Loop
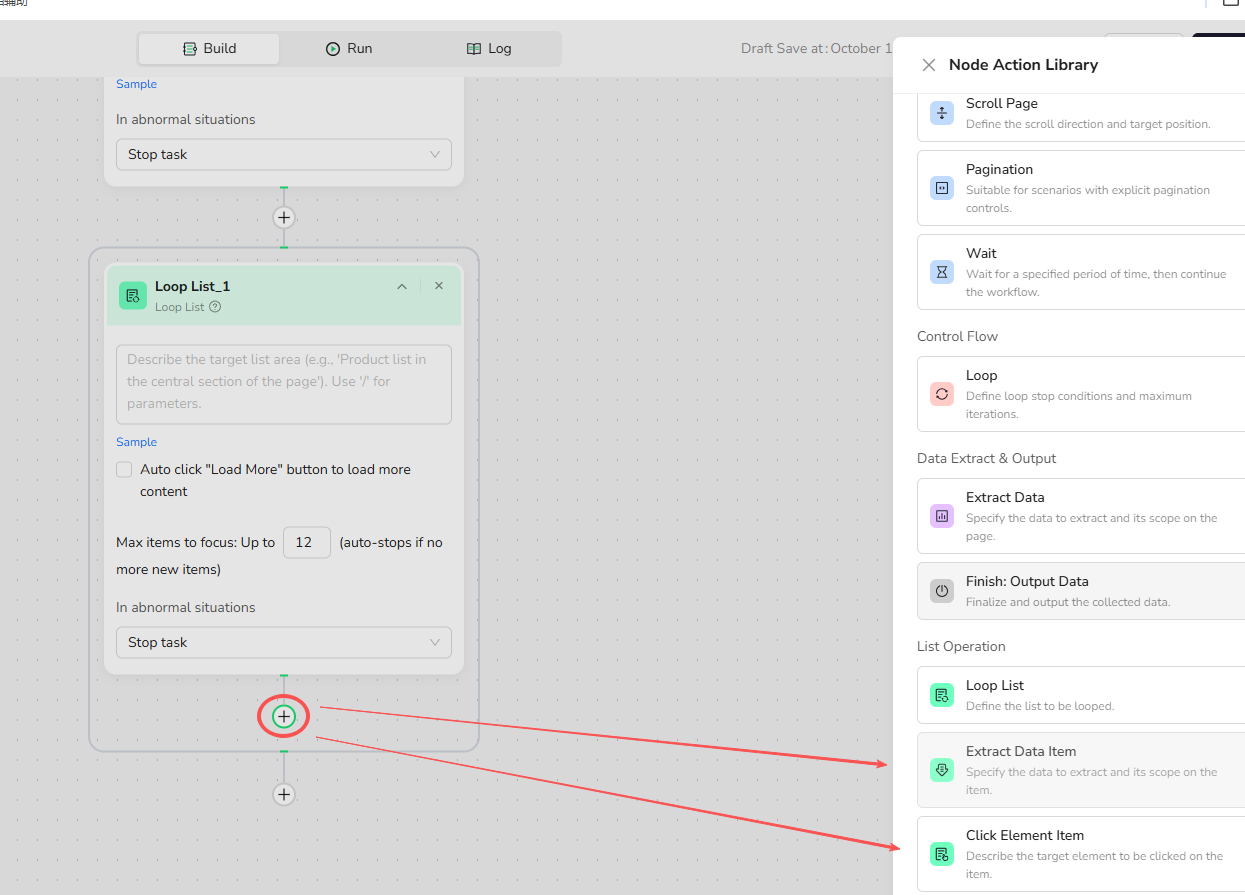
- Extract Data Item: · Use this to grab specific data from the current list item. (E.g., product title, price, etc.)
- Click Element Item: · Use this to click something specific inside the item (for example, a "details" or "comments" button) to get more information.
- Extract Data Item: · Use this to grab specific data from the current list item. (E.g., product title, price, etc.)
4. Handle Nested or Detail Pages (If Needed)
If you want to go deeper—like getting more details from a separate page for each item—just add another Loop List or Extract Data node inside your current workflow. Loop List supports up to 3 levels of nesting.
5. Exporting Results
Once you finish the loop, you can output your results as a CSV or pass them to the next step in your automation.
Example: Scraping Reddit Posts
Goal: Gather titles, upvotes, and comment counts from search results.
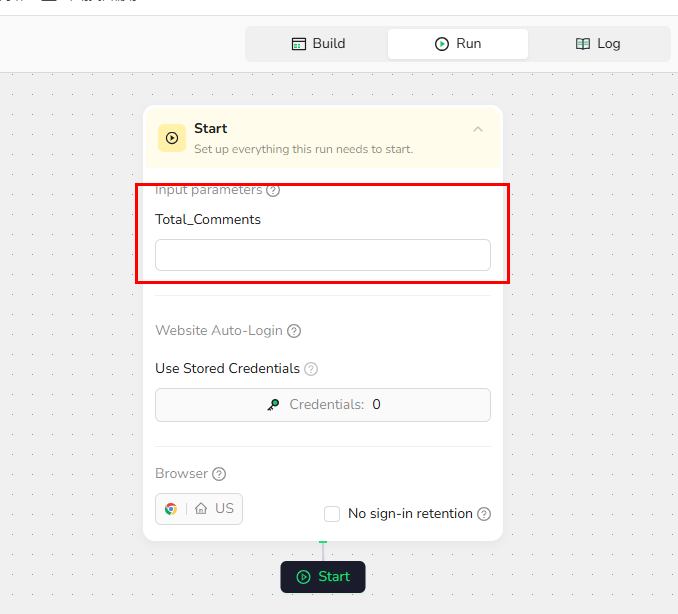
1.Start Node Parameter Settings
Total_Comments: Set the number of comments to extract, e.g., 10.
Note: You can adjust this value based on your needs. If you want to extract all comments under a post, you can delete this variable
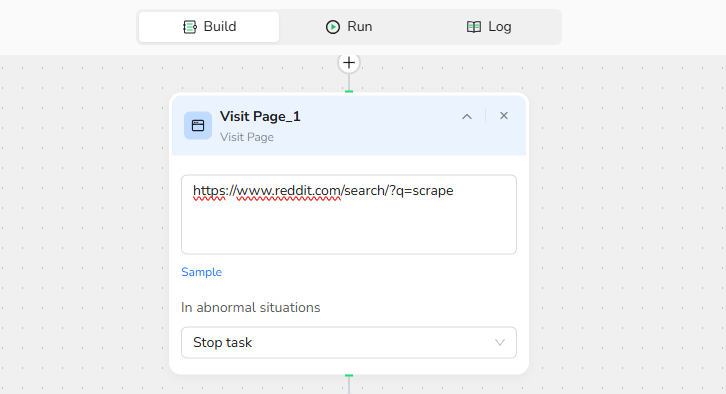
2.Visit Page:
Enter the URL "https://www.reddit.com/search/?q=scraper" to navigate to the target website.
3.Add Loop List Node
Loop List Node Basic Settings
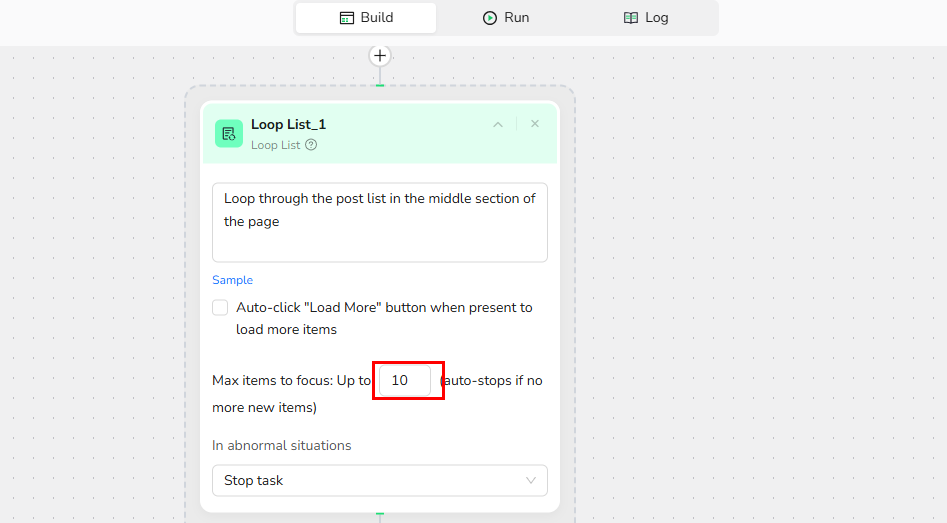
- List Region Description: Loop through the post list in the middle section of the page.
- Load More: Unchecked. (The page uses automatic loading, so there's no need to click "Load More", therefore this option should remain unchecked)
- Max Focused Loop Items: Limit the number of posts to process; adjustable, e.g., 10.
Note: The number of focused items here represents the number of posts you want to extract. For example, if you want to extract 20 posts, adjust this value to 20.
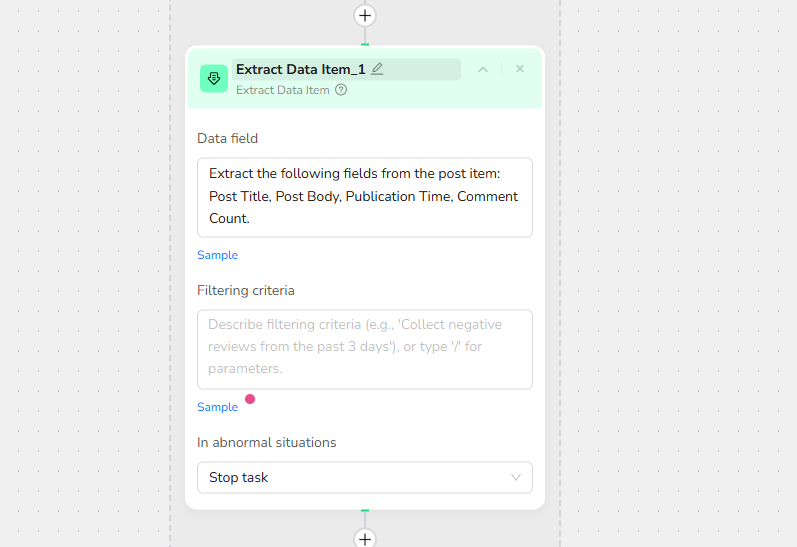
4.Add Extract Data Item:
Data Field: Extract the following fields from the post item:Post Title, Post Body, Publication Time, Comment Count.
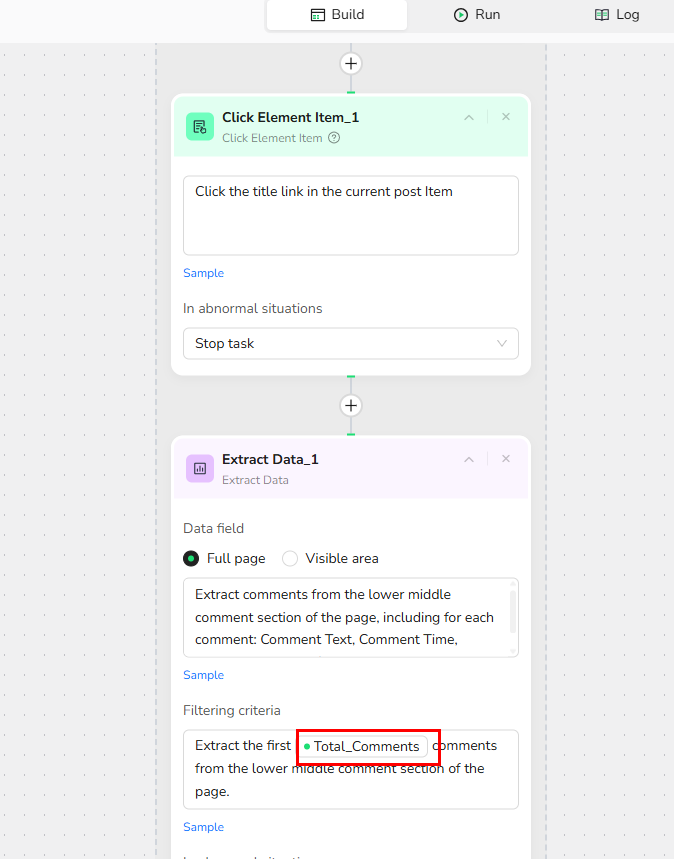
4 . Add Click Element Item:
Click the title link in the current post Item
5.Add Extract Data:
Data Field: Extract comments from the lower middle comment section of the page, including for each comment: Comment Text, Comment Time, Commenter. Use 'N/A' for any missing fields.
Note: You can specify the exact location of the data to be collected on the page to increase the accuracy of data extraction.
Filtering Criteria: Extract the first {{Total_Comments}} comments from the lower middle comment section of the page.
mber of comments you want to extract.
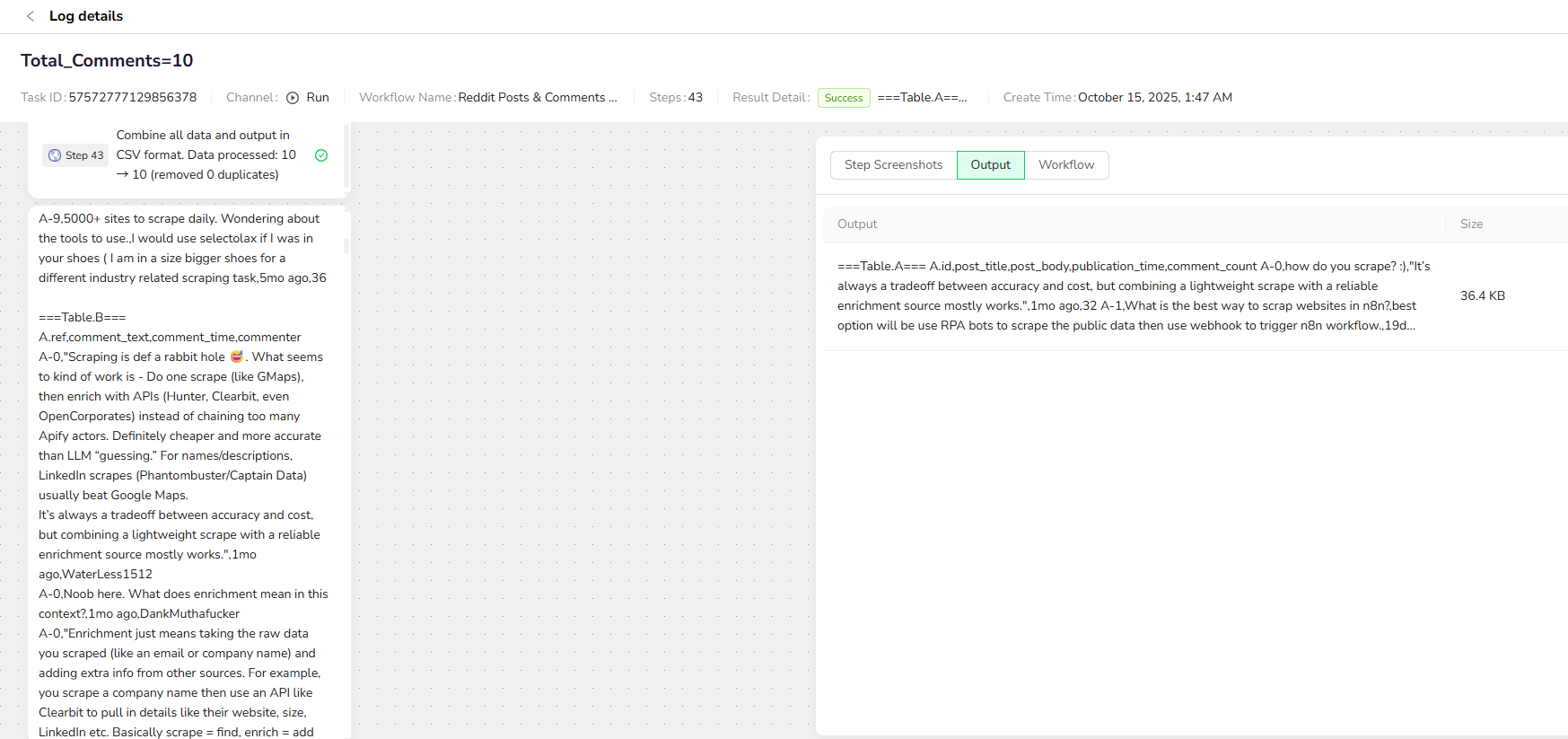
6.Output Data:
Choose from multiple format options to suit your needs:JSON,CSV,XML,Markdown (MD)
Notes:
- Each extraction step outputs independent data, supporting modular workflows.
- When extracting different content from the same page, add two Extract Data nodes to extract content in stages, ensuring data accuracy (e.g., extract comments first, then other fields).
Key Rules & Best Practices
· Only one Loop List node per level, with up to 3 levels nested
· Loop List needs at least one sub-node (Extract Data or Click Element)
· Each Loop List can have one Extract Data Item
· If your list is dynamic or paginated, use the "Load More" feature
Tips for Success
· Always clearly describe the list region.
· Set your Max Focused Loop Items wisely: Too high can mean long waits, too low may miss data.
· For highly dynamic content, check if "Load More" or pagination is needed.
Quick Review
· What does "Max Focused Loop Items" control?
· When should you use the "Load More" setting?
· Can you nest Loop List nodes, and how deep?
Once you've walked through these steps, try setting up your own simple workflow. If you run into trouble, what part of the set-up do you feel least confident about?
If you tell me your current project or the exact site you want to automate, I can walk you through an even clearer, personalized example.
Need help? Contact BrowserAct support or consult our documentation for more automation tips.
- Discord: [Discord Community]
- E-mail: service@browseract.com

Relative Resources




Latest Resources

BrowserAct vs Skyvern: Open-Source Browser Agent vs Managed Workflow

BrowserAct vs Selenium in 2026: Is It Time to Move On?

BrowserAct CAPTCHA Handling vs 2Captcha vs CapSolver: Real Cost Comparison
