How to Use the BrowserAct Loop List Node

Master BrowserAct's Loop List node for visible region list traversal, nested extraction, and dynamic adaptation. Ideal for Reddit posts, Amazon products, and job scraping. Learn features, rules, and real-world examples to streamline automation workflows and boost data collection efficiency.
Function Overview
The Loop List node supports locating lists within the visible region and iterating through them, sequentially focusing on each Item and its detail page, with up to 3 levels of nested data extraction. When the maximum number of focused items is reached or no more new items are available, it stops executing nodes within the loop body and continues with subsequent nodes outside the loop. This node is particularly suitable for sequential data traversal and collection in automation workflows, enabling precise data extraction without manual intervention.
Key Features
- List Deep Dive: Automatically opens secondary detail pages for list Items, performs data extraction, and seamlessly returns to the list view after completion to process the next Item.
- Dynamic Adaptation: Automatically adjusts to page changes, such as auto-loading in waterfall layouts, ensuring a seamless extraction process without manual intervention.
- Auto-Load More: When the "Load More" option is checked, it automatically clicks the "Load More" button to fetch additional Items, efficiently expanding the dataset.
- Smart Detection: Automatically identifies target list elements within the visible viewport, reducing mis-extractions and improving accuracy in dynamic environments.
- Duplicate Prevention: Automatically skips identical items during extraction to avoid data redundancy, enhancing workflow performance and data quality.
Applicable Scenarios (Examples)
Suitable for sequential data traversal and collection in automation workflows, efficiently handling dynamic lists. Examples include:
- Extracting Reddit posts and comments for sentiment analysis workflows.
- Extracting Amazon product lists for e-commerce monitoring automation.
- Extracting job lists and details for recruitment automation processes.
Usage Rules
- Loop List supports a maximum of 3 nested levels.
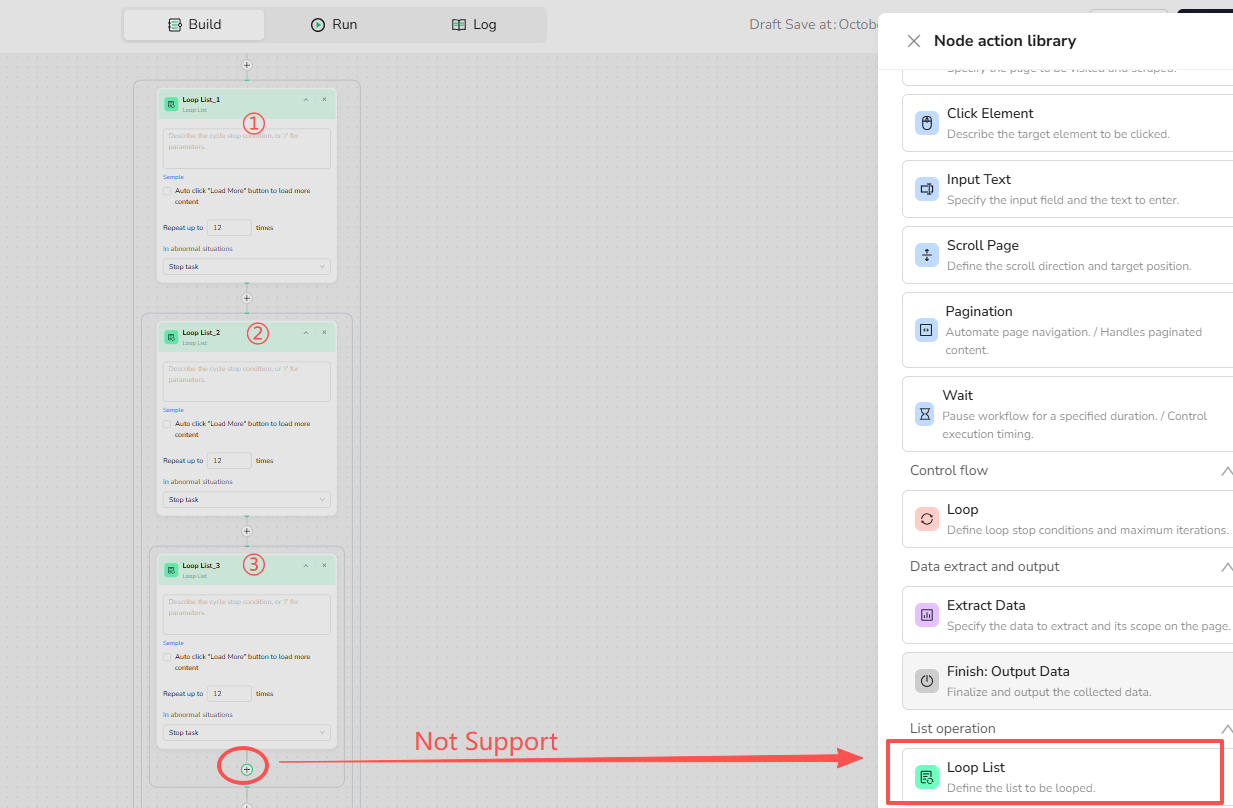
- Only one Loop List node can be added per level.
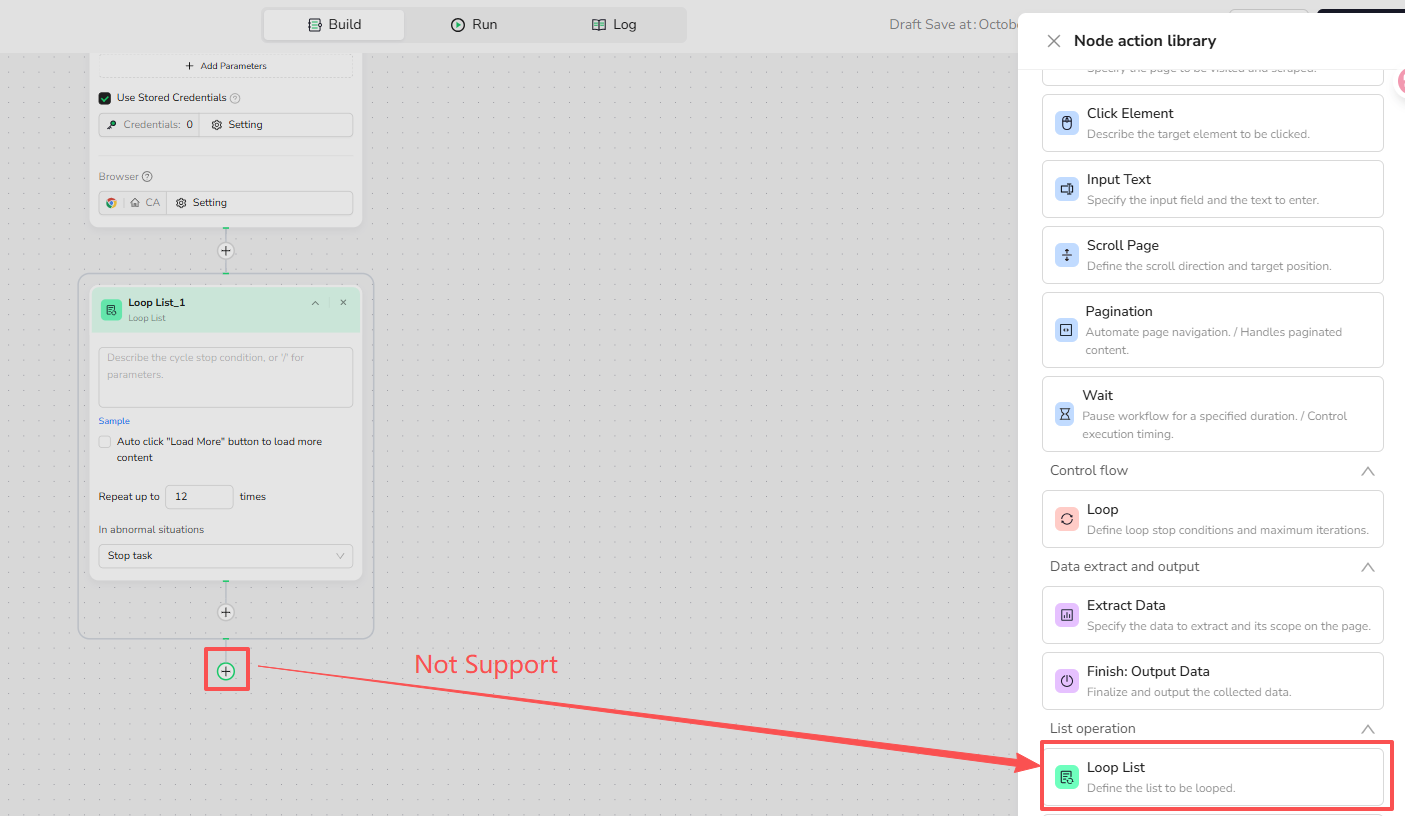
- Exclusive sub-nodes (Extract Data Item and Click Element Item) are only applicable to Loop List and cannot be used in other locations.
- Each Loop List can include at most one Extract Data Item.
- Each Loop List requires at least one sub-node.
Operation Guide
- Click the + button and select the Loop List node from the node library.
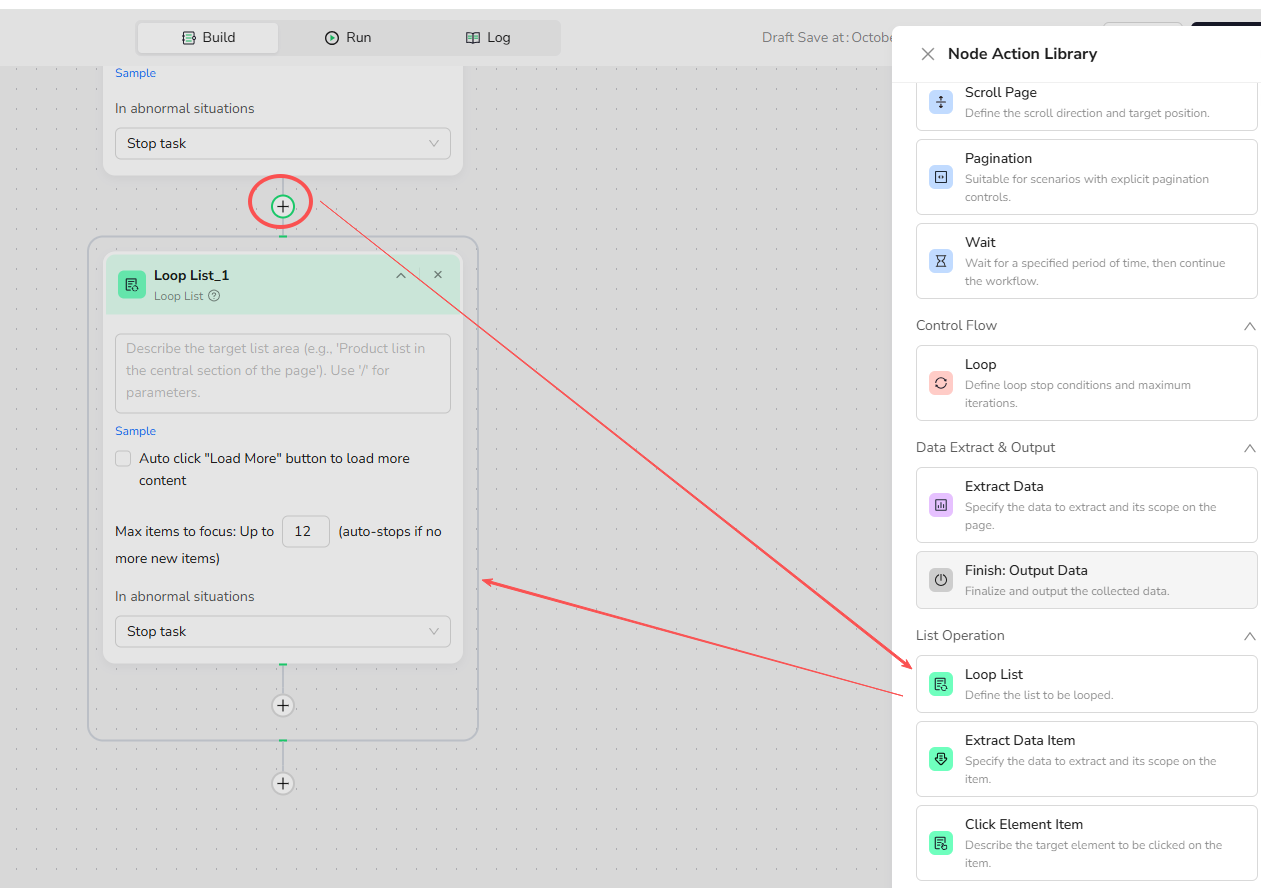
- Complete the basic Loop List settings:
- List Region Description: Define the target area, e.g., "Job listings in the middle section of the page."
- Load More: Check only if the page has a "Load More" button or pagination; this automates scrolling or clicking to fetch additional items.
- Max Focused Loop Items: Set the maximum number of iterations. Defaults to 10, with a maximum of 999. The loop exits when the set number is reached. Adjust based on page content:
- If extracting more data than the number of items in the list, set the value ≥ the actual number of items.
- If extracting fewer data than the actual list on the page, enter the required number of data to extract.
- Example: For extracting 100 items across pages with 23 per page, set to 23; for a waterfall page extracting only 10 items, set to 10.
- Add nodes inside the Loop List:
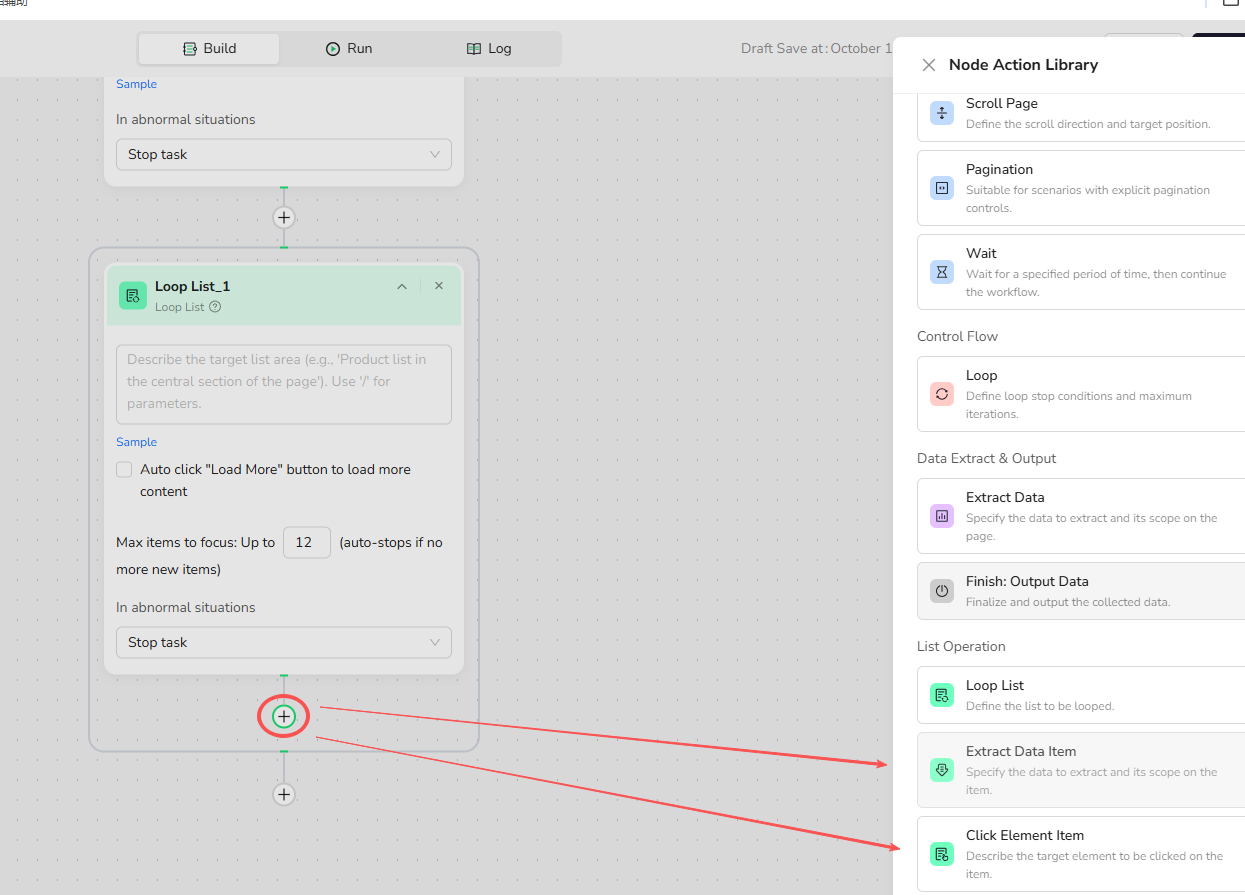
- Extract Data Item: Used to extract data from the current Item.
Prompt example: " Extract the following fields from the page: Topic/Title, Forum Location, Votes/Upvotes, Comment Count. Use 'N/A' for any missing fields.
- Click Element Item: Used to perform click operations on Items; enter the instruction in the text box, e.g., "Click the title link in the current focused job Item."
- Extract Data Item: Used to extract data from the current Item.
Examples
Case 1: Extracting Himalayas Customer Service Job Information
Specific Operation Steps:
1.Start Node Parameter Settings:
Data_Limit: 30
2.Visit Page: Enter the URL https://himalayas.app/jobs/customer-service to navigate to the target website.
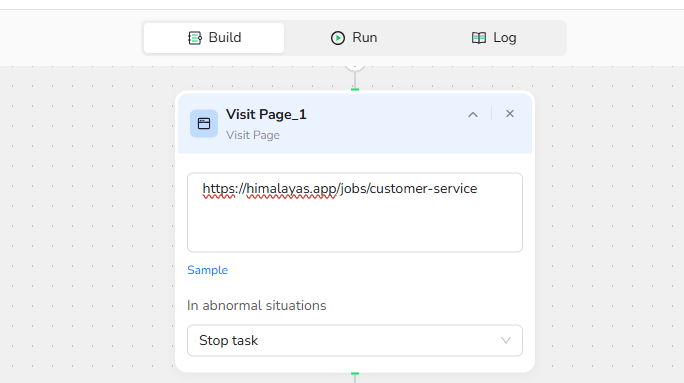
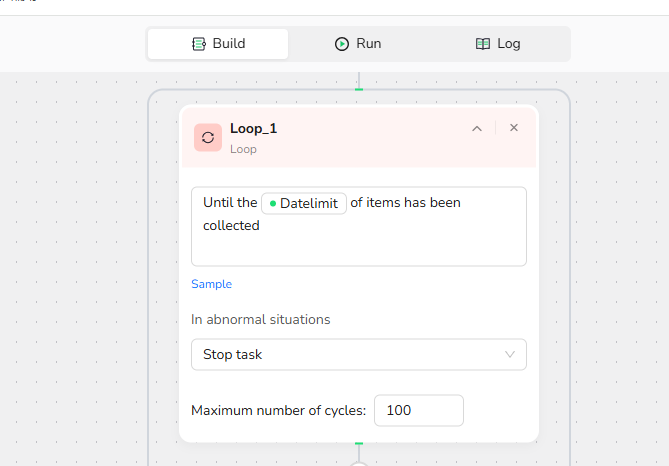
3.Add Loop Node:
3.1 Input Loop Stop Condition: Until the {{datelimit}} of items has been collected.
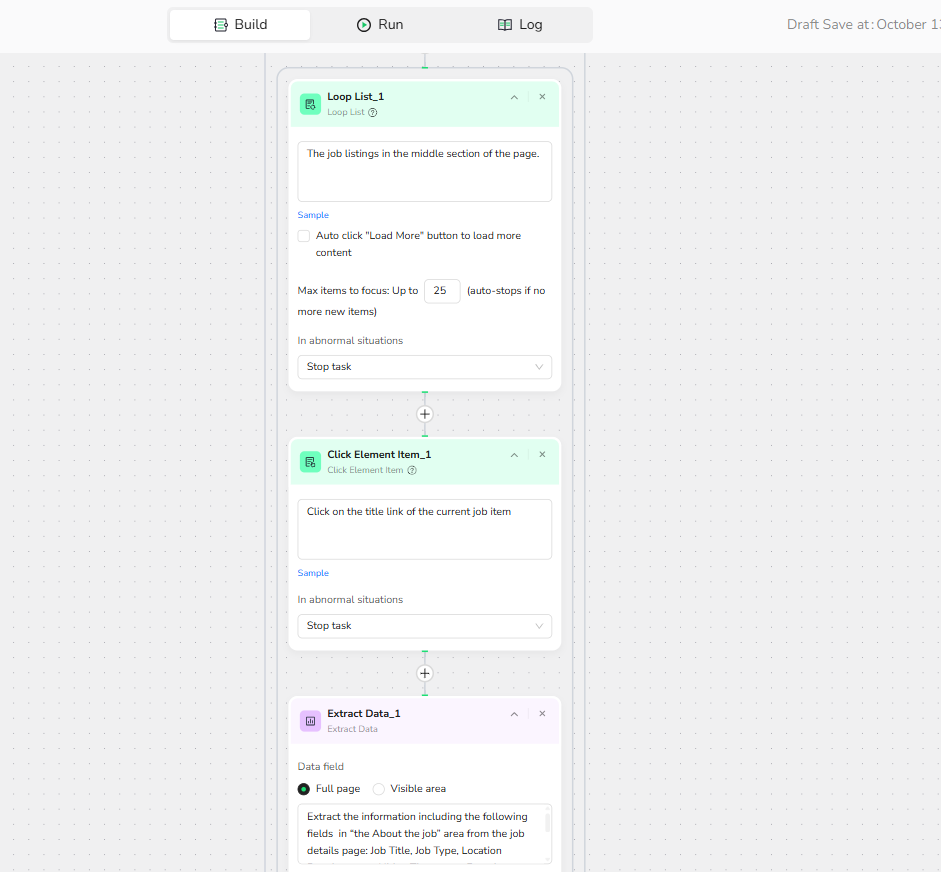
3.2 Add Loop List Node:
3.2.1 Loop List Node Basic Settings
- List Region Description: The job listings in the middle section of the page.
-Load More: Unchecked.
-Max Focused Loop Items: 23 (based on page Item count).
3.2.2 Add Click Element Item: Click the title link in the current focused job Item.
3.2.3 Add Extract Data:
Data Field: Extract the information including the following fields in “the About the job” area from the job details page: Job Title, Job Type, Location Requirements, Hiring Timezones, Experience Level, Contract, Job Categories, Skills, Company Size, Company Name. For any missing fields, use 'N/A' as the value
3.3 Add Pagination: Select "Next page" to handle multi-page navigation.
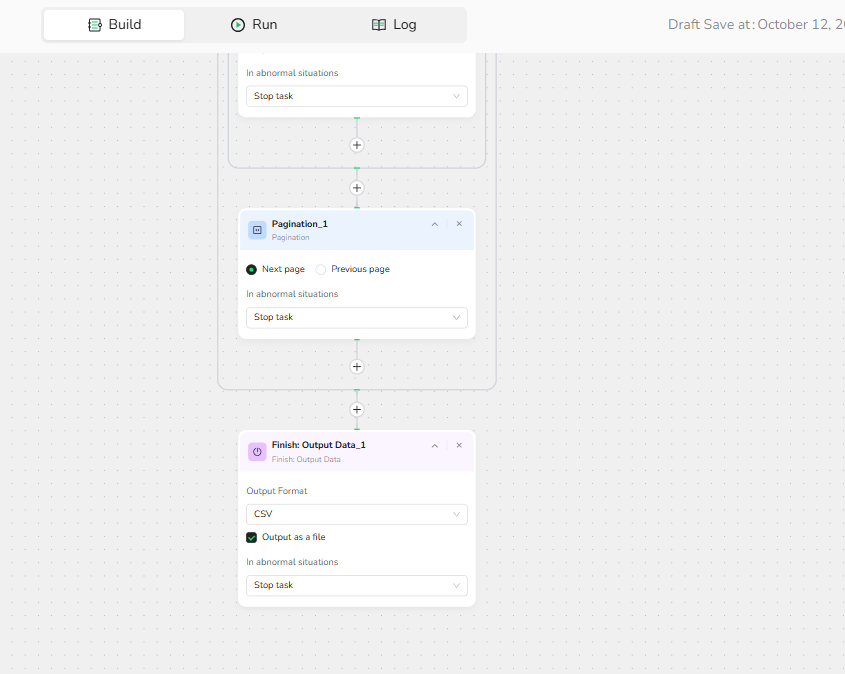
4.Output Data
Select CSV file format for output.
Result Example:
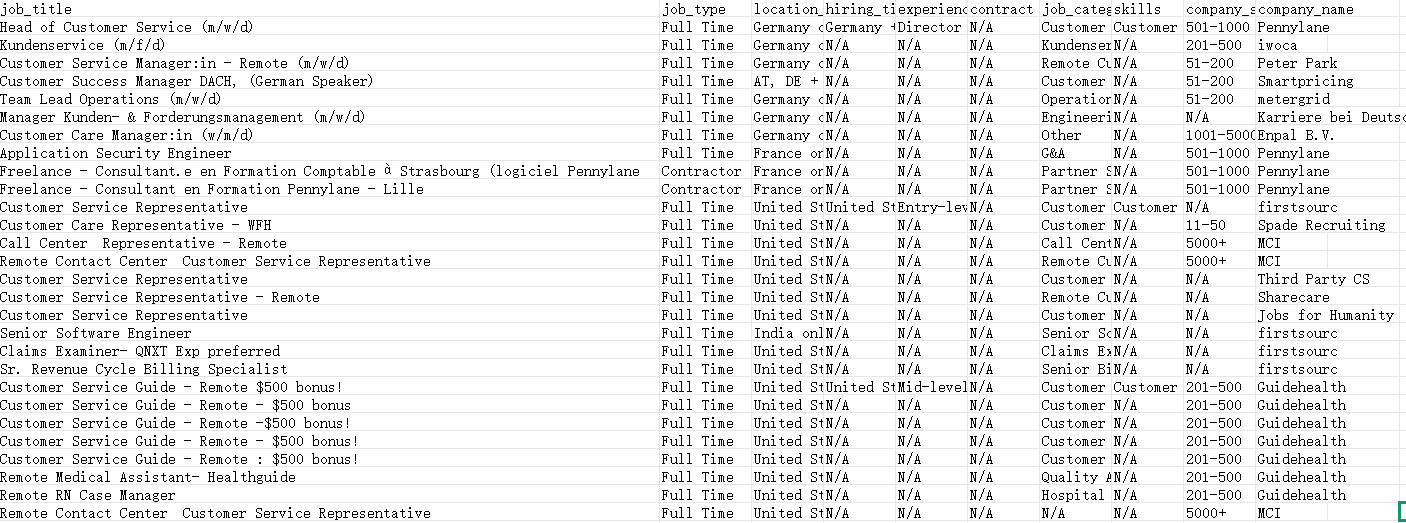
Case 2: Reddit Post and Comment Extraction
Specific Operation Steps:
1.Start Node Parameter Settings
Data_Limit: Set the number of comments to extract, e.g., 10.
2.Visit Page: Enter the URL "https://www.reddit.com/search/?q=scraper" to navigate to the target website.
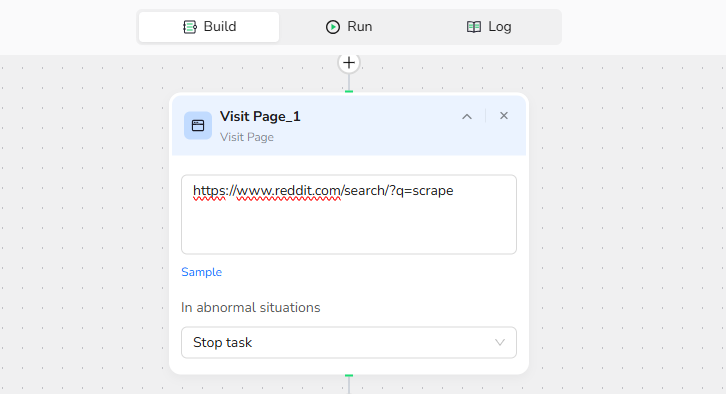
3.Add Loop List Node:
3.1 Loop List Node Basic Settings:
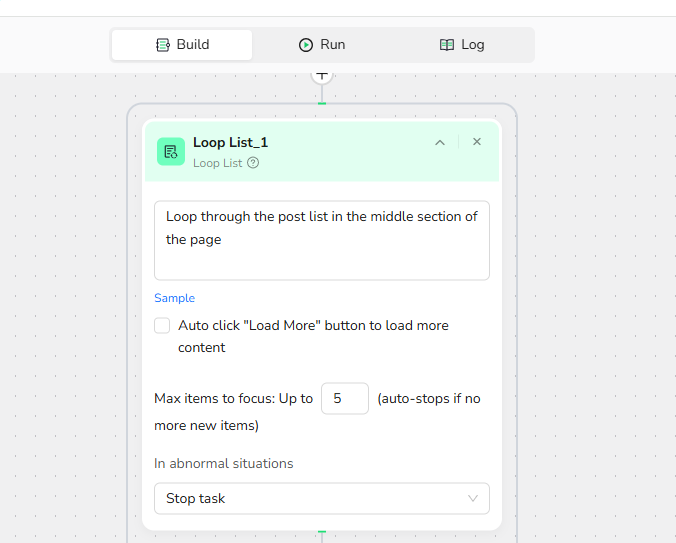
- List Region Description: Loop through the post list in the middle section of the page.
- Load More: Unchecked.
- Max Focused Loop Items: Limit the number of posts to process; adjustable, e.g., 5.
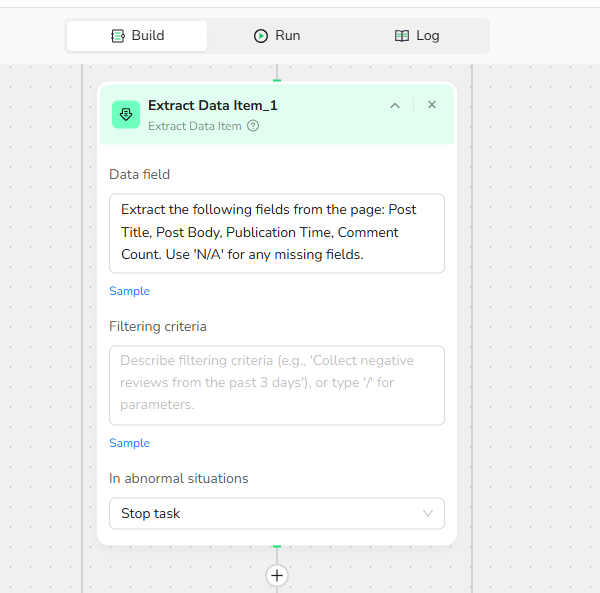
3.2 Add Extract Data Item:
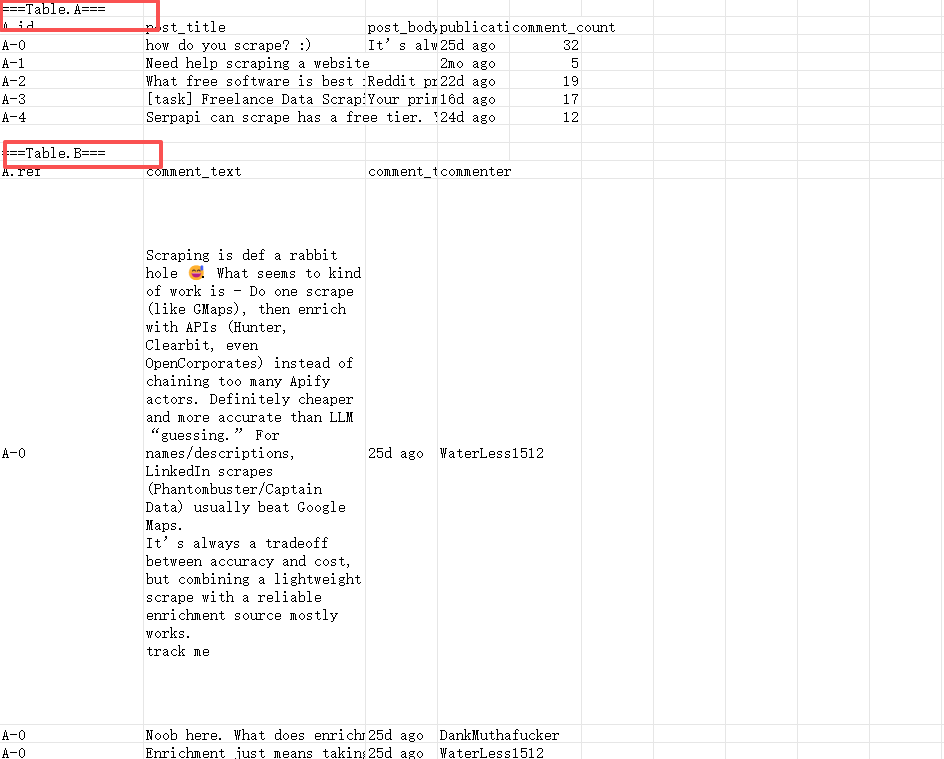
Data Field: Extract the following fields from the page: Post Title, Post Body, Publication Time, Comment Count. Use 'N/A' for any missing fields.
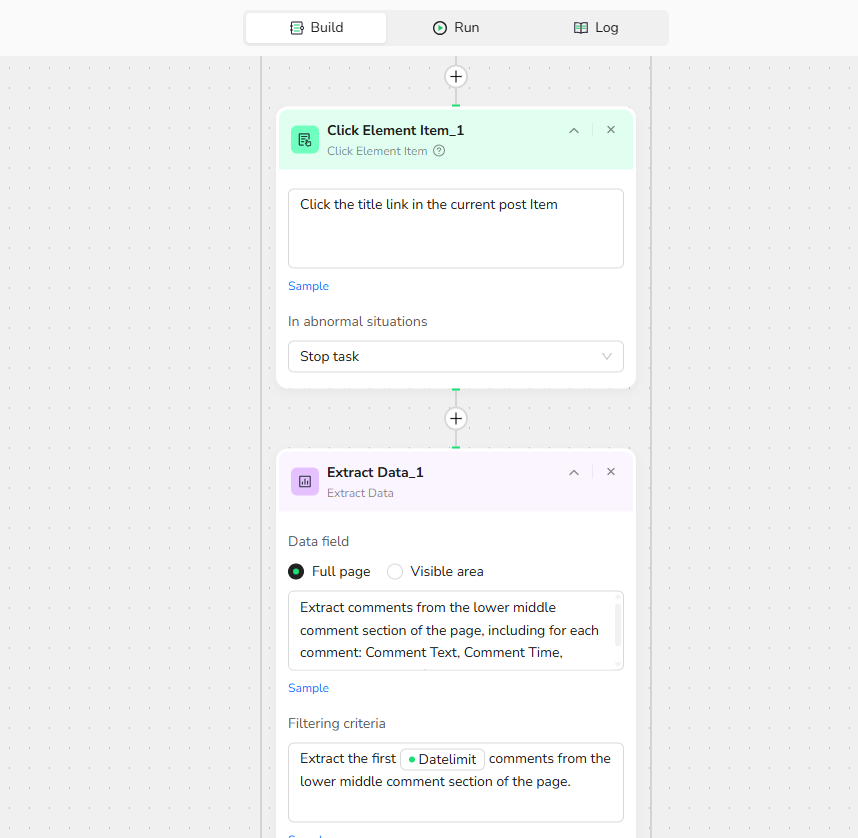
3.3 Add Click Element Item: Click the title link in the current post Item
3.4 Add Extract Data:
Data Field: Extract comments from the lower middle comment section of the page, including for each comment: Comment Text, Comment Time, Commenter. Use 'N/A' for any missing fields.
Filtering Criteria: Extract the first {{datelimit}} comments from the lower middle comment section of the page.
4.Output Data:
Select CSV file format for output.
Result Example:
Notes:
- Each extraction step outputs independent data, supporting modular workflows.
- When extracting different content from the same page, add two Extract Data nodes to extract content in stages, ensuring data accuracy (e.g., extract comments first, then other fields).
FAQ
1.What's the difference between Loop and Loop List?
Loop is a general iteration node for simple repetitions (e.g., fixed times), while Loop List is specifically designed for list-based workflows, supporting nesting and dynamic Item processing (e.g., scraping variable-length lists).
2.How many Loop List nodes can be added in one workflow?
Each branch supports a maximum of 3 nested levels, with only one per level to avoid conflicts.
3.What is the maximum nesting level supported by Loop List?
Loop List supports a maximum of 3 nested levels.
Need help? Contact BrowserAct support or consult our documentation for more automation tips.
- Discord: [Discord Community]
- E-mail: service@browseract.com

Relative Resources

BrowseAct Professional Workflow Guide

BrowseAct Workflow is Now Live! More Accurate Data, Lower Costs!

How to Use BrowserAct's Credential Management Feature

Quick Start Guide- Build Agent for Task Optimization
Latest Resources

BrowserAct Shopify Product Scrapers — Data Collection for Every Store

AI‑Driven Procurement Cost Reduction Workflow for Smarter Supply Chain Management

How to Set Up LinkedIn Two-Factor Authentication in BrowserAct
