Case Study: Building an Amazon Product Data Extraction Agent

Learn how to develop reliable Amazon product data extraction agents through iterative optimization, handling common challenges, and implementing best practices for automated data collection.
Introduction
In today's competitive e-commerce landscape, businesses need efficient ways to gather product data from platforms like Amazon. Manual data collection is time-consuming and error-prone, making automated extraction agents essential for market research, competitive analysis, and pricing strategies. This comprehensive guide walks you through building a robust Amazon product data extraction agent that handles common challenges and delivers reliable results.
The key to successful agent development lies in understanding that you don't need perfect system instructions from the start. Instead, follow the core principle of running tasks first, then optimizing based on the gap between your results and expectations. This iterative approach leads to more effective and reliable agents.
Understanding Common Challenges
Before diving into the solution, it's crucial to understand the typical problems that arise when extracting data from Amazon:
Step Errors and Redundancy
One of the most common issues is repetitive operations where the agent gets stuck in loops. For example, repeatedly clicking the same product on Amazon listing pages, or getting trapped in endless retry cycles. These redundancies waste computational resources and can trigger Amazon's anti-bot measures.
Extraction Errors
Missing or incorrect data extraction occurs when the agent fails to locate required fields like product names, prices, or ratings. This often happens due to Amazon's dynamic page structures, where elements may load asynchronously or appear in different locations depending on the product type.
Output Format Errors
Even when data extraction succeeds, the output may not match requirements. Common issues include wrong file formats, incorrect column ordering, or inconsistent data formatting that makes the results difficult to analyze.
The Initial Setup and First Run
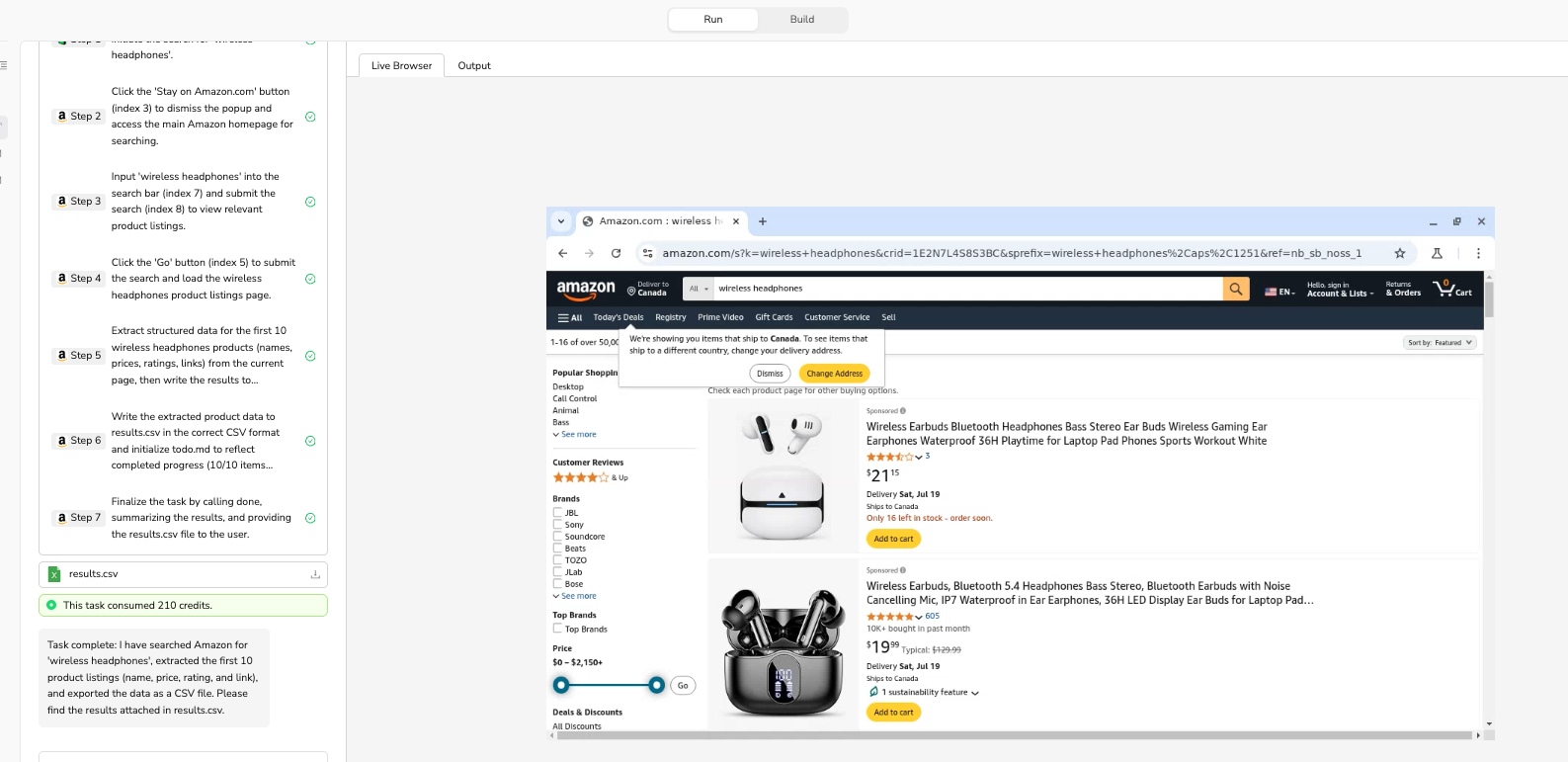
Let's start with a practical example. Your initial user task might look like this:
Search Amazon for "wireless headphones" category, extract the first 10 products' names, prices, ratings, and
links, then export as CSV file.
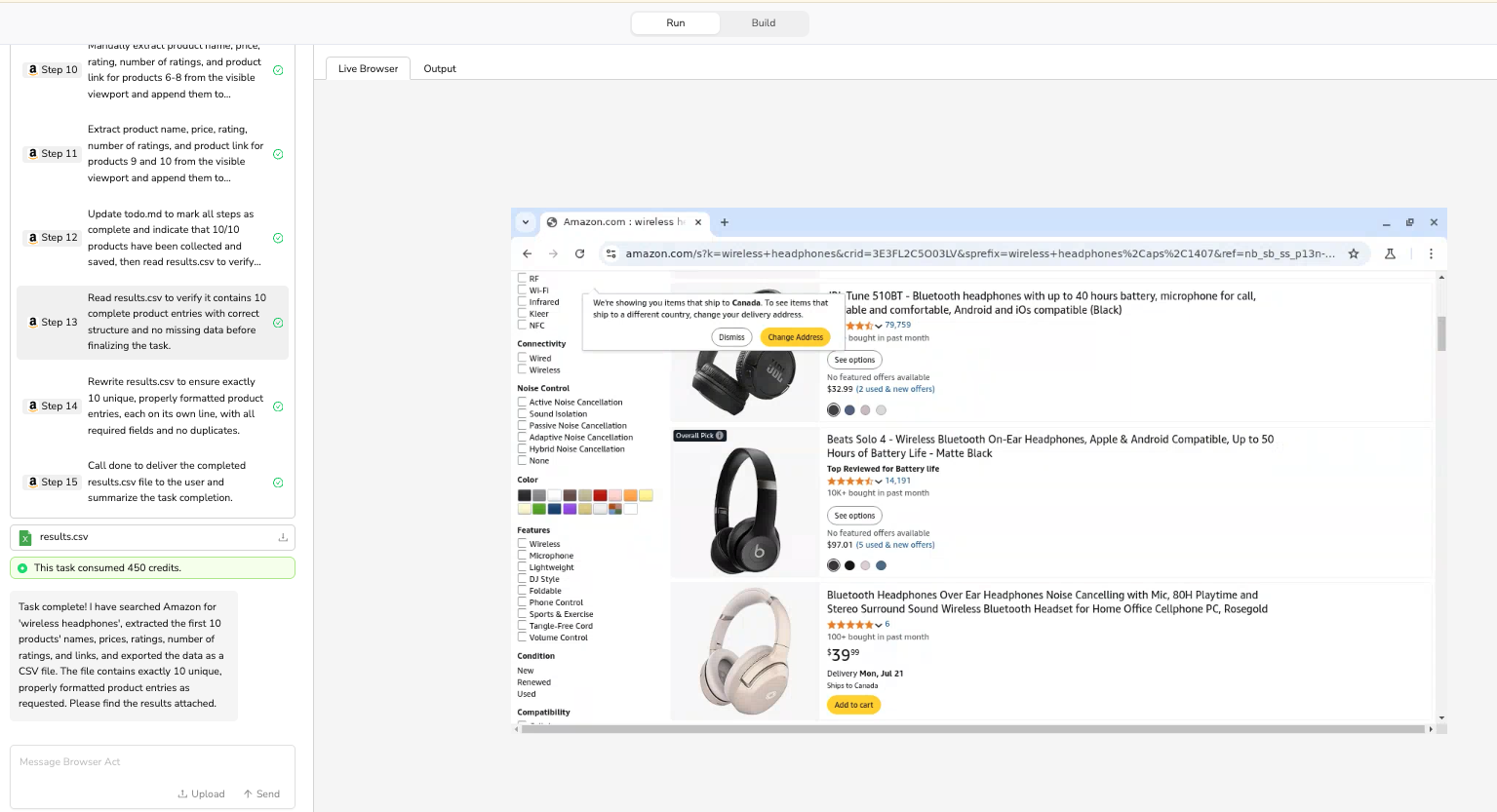
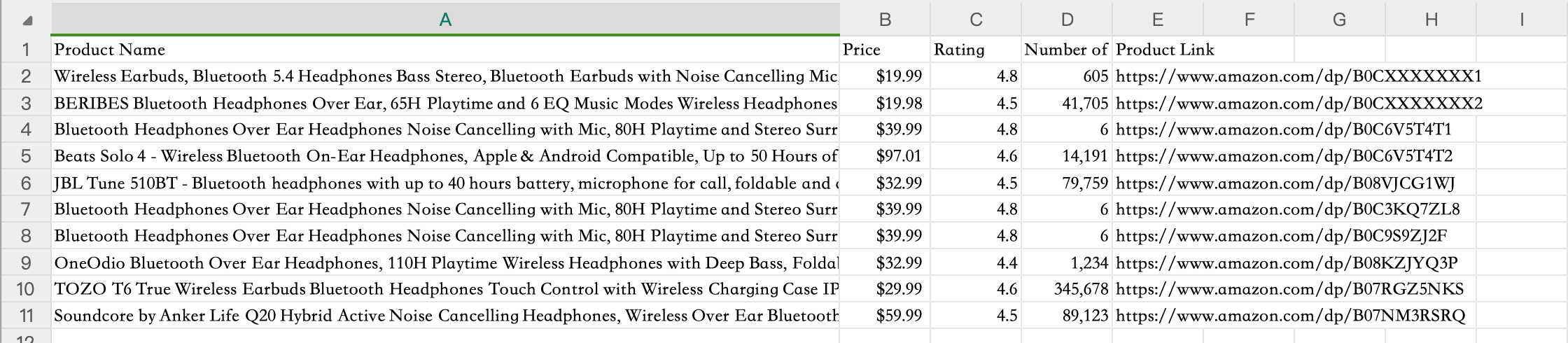
When you run this task without any system instructions, you'll likely encounter the problems mentioned above. The agent might click the same product multiple times, miss rating data, and export a CSV file with columns in the wrong order. This is expected and provides valuable information for optimization.
Building Optimized System Instructions
Based on the initial results, you can now create targeted system instructions using a structured approach: Condition-Requirement-Constraint. Here's how to build comprehensive system instructions for your Amazon extraction agent:
Extraction Process Optimization
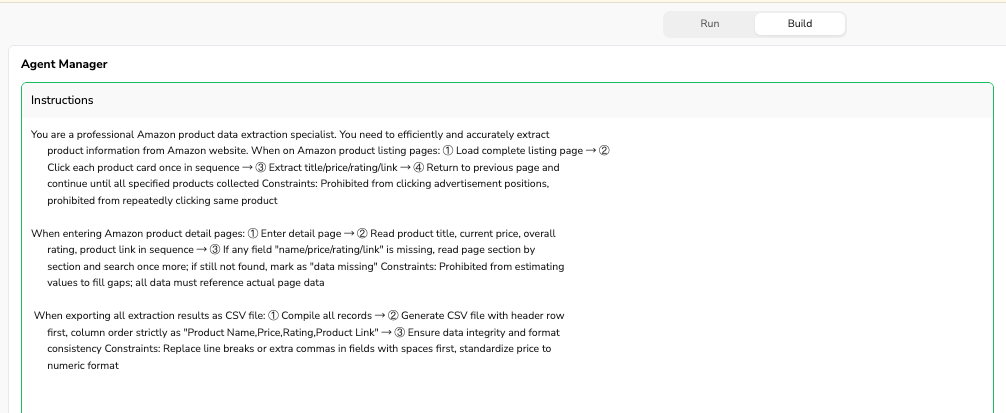
You are a professional Amazon product data extraction specialist. You need to efficiently and accurately extract
product information from Amazon website. When on Amazon product listing pages: ① Load complete listing page → ②
Click each product card once in sequence → ③ Extract title/price/rating/link → ④ Return to previous page and
continue until all specified products collected Constraints: Prohibited from clicking advertisement positions,
prohibited from repeatedly clicking same product
This section addresses step errors by providing clear sequential instructions and explicitly prohibiting redundant actions. The constraint prevents the agent from clicking ads, which could derail the extraction process.
Data Extraction Standards
When entering Amazon product detail pages: ① Enter detail page → ② Read product title, current price, overall
rating, product link in sequence → ③ If any field "name/price/rating/link" is missing, read page section by
section and search once more; if still not found, mark as "data missing" Constraints: Prohibited from estimating
values to fill gaps; all data must reference actual page data
This addresses extraction errors by defining a systematic approach to data collection and establishing fallback procedures when information is missing. The constraint ensures data integrity by preventing the agent from making up values.
Output Format Control
When exporting all extraction results as CSV file: ① Compile all records → ② Generate CSV file with header row
first, column order strictly as "Product Name,Price,Rating,Product Link" → ③ Ensure data integrity and format
consistency Constraints: Replace line breaks or extra commas in fields with spaces first, standardize price to
numeric format
This section ensures consistent output formatting and handles edge cases that could corrupt the CSV file structure.

Quality Assurance Guidelines
To maintain high data quality, include specific formatting requirements:
- Each product must include 4 fields: name, price, rating, link
- Price format: Keep only numbers and decimal points, remove currency symbols
- Rating format: X.X/5.0 or mark as "data missing"
- Link format: Complete Amazon product URL
Optimized User Task Instructions
Along with system instructions, refine your user task prompts to be more specific and actionable:
Objective: Search Amazon for "wireless headphones", extract complete information for the first 10 products,
Complete within 30 steps. Specific Requirements: 1. Search keyword: "wireless headphones" 2. Extract fields:
Product Name, Price, Rating, Product Link 3. Product quantity: First 10 products 4. Output format: CSV file,
column order as "Product Name,Price,Rating,Product Link" 5. Step limit: Complete within 30 steps 6. Data quality:
Ensure each field has data or mark as "data missing." Begin task execution.
This refined approach provides clear objectives, specific requirements, and measurable success criteria, making it easier for the agent to understand and execute the task correctly.
Model and Temperature Configuration
For Amazon product extraction tasks, specific model and temperature settings optimize performance:
Setting | Recommendation | Reason |
Model | GPT-4.1-Mini | Cost-effective for structured data extraction tasks |
Temperature | 0.1 - 0.3 | Low randomness ensures consistent, accurate data extraction |
Use GPT-4.1-Mini for simple, well-defined extraction tasks as it provides reliable results at lower cost. Reserve GPT-4.1 for complex scenarios involving multiple site structures or when handling CAPTCHAs and infinite scroll pages.
Iterative Optimization Process
The optimization process typically involves multiple iterations. Here's what a complete optimization workflow looks like:
Initial State
- System Instructions: Empty
- First Run Results: 45 steps, 60% success rate, multiple issues with repeated clicks and missing data
First Optimization
Add step control instructions to prevent redundant operations.
- Second Run Results: 32 steps, 75% success rate, reduced redundancy, but data quality issues remain
Second Optimization
Add data quality control specifications for proper formatting and missing data handling.
- Third Run Results: 28 steps, 90% success rate, improved data qualit, but output format needs adjustment
Final Optimization
Add output format control for proper CSV structure and data cleaning.
- Final Results: 25 steps (44% reduction), 95% success rate, complete CSV file with proper formatting
Best Practices and Tips
System Instructions Writing
- Use a layered structure grouping by functional modules (extraction, processing, output)
- Define specific constraints, clearly stating what can and cannot be done
- Include exception handling for missing data and page errors
- Set quality standards for data format and completeness requirements
Common Pitfalls to Avoid
- Overcomplicating initial instructions before testing basic functionality
- Adding constraints without first running tests to identify actual problems
- Ignoring cost versus performance trade-offs in model selection
- Not specifying clear output requirements and data formats
- Failing to handle edge cases like missing data or format variations
Performance Optimization
- Start simple with basic functionality, then add complexity gradually
- Use iterative testing: Run → Identify issues → Optimize → Repeat
- Monitor costs and balance model choice with budget constraints
- Validate outputs to ensure data quality meets business requirements
- Document changes to track what works and what doesn't
Conclusion
Building an effective Amazon product data extraction agent requires a systematic approach focused on iterative improvement rather than a perfect initial design. By starting with basic functionality and optimizing based on actual performance gaps, you can create robust agents that deliver reliable, high-quality data.
The key success factors include clear system instructions with proper condition-requirement-constraint structure, specific user task prompts with measurable criteria, appropriate model and temperature settings for the task type, and continuous optimization based on real-world testing results.
Remember that the goal is to systematically bridge the gap between expectation and reality through optimization, not to create perfect instructions from the start. This pragmatic approach leads to more effective agents that can handle the complexities and variations inherent in web scraping tasks.
With these guidelines and best practices, you can build Amazon extraction agents that consistently deliver the product data you need for market research, competitive analysis, and business intelligence applications.

Relative Resources




Latest Resources

Costco Wholesale Corporation Headquarters and Address

How to Research Instagram Creators with a Prompt—No Scraper Code

How to Monitor X Trends with a Prompt and a No-Code Cloud Bot
