How to scrape xxxx video by chat without code

Learn how to efficiently scrape XXXX video content using BrowserAct’s AI-powered no-code automation. This comprehensive guide covers metadata extraction, video filtering strategies, performer intelligence, technical indicators, and best practices for ethical scraping. Discover the best tools like yt-dlp, Scrapy, and FFmpeg for building a high-quality video scraping pipeline.
So you want to scrape xxxx videos? You've come to the right place. Whether you're building a personal collection, conducting research, or automating content workflows, xxxx video scraping can be both powerful and tricky.

Technical Complexity of Video Scraping
Video scraping isn't as straightforward as grabbing text from a webpage. You're dealing with multiple layers of complexity that can make your head spin if you're not prepared.
The Core Skills You Actually Need
1. Web Technologies Foundation You can't scrape what you don't understand. Here's the bare minimum:
- HTML/CSS: How websites structure their content
- HTTP/HTTPS protocols: Understanding requests, responses, and headers
- Browser DevTools: Your best friend for debugging and reverse engineering
2. Programming Language Proficiency Pick one and get good at it:
- Python: Most popular for scraping (Beautiful Soup, Scrapy, Selenium)
- JavaScript/Node.js: Great for handling modern web apps
3. Asynchronous Programming Video scraping is slow. You need to understand:
- Concurrent requests: Don't wait for one video to finish before starting the next
- Rate limiting: How to not get banned while staying efficient
- Queue management: Processing thousands of videos without crashing
BrowserAct for Video Scraping: No-Code Solution with AI-Powered Automation
Now, let's talk about the game-changer: BrowserAct. If you're not a programmer or just want to get things done fast, this is your new best friend.
Why Choose BrowserAct Over Traditional Coding Methods
Traditional scraping requires you to write code, debug issues, and maintain your scripts. BrowserAct flips this on its head:
- No coding required: You describe what you want in plain English
- Visual workflow: See exactly what your bot is doing
- AI-powered: It figures out how to interact with websites automatically
- Handles updates: When websites change, it adapts without you rewriting code
The Smart Scraper's Approach
Don't just rely on title keywords. The xxxx Video Scraper gives you access to:
Essential Metadata
- Xxxx Video title and description analysis
- Xxx View count and engagement metrics
- Upload and added dates
- Associated channel information
Content Intelligence
- Categories and tags (official classifications)
- Production information (amateur vs. professional)
- Model attributes and featured performers
- Video quality indicators (resolution, duration)
Quality Indicators
- Like/dislike ratios
- Favorites count
- Comment engagement
- Channel subscriber count
Setting Up Your Filtering Strategy
Here's how to build a filter system that actually works:
- Define your niche clearly - What specific content type are you targeting?
- Set quality thresholds - Minimum views, like ratios, resolution standards
- Use category filters - Leverage official site categorization
- Apply performer filters - Consistent content style through performer selection
- Time-based filtering - Fresh content vs. classic material preferences
🎯 The Smart XXXX Video Scraper's Approach
Don't just rely on title keywords. The XXX Video Scraper gives you access to comprehensive XXX video intelligence:
📊 Essential XXX Video Metadata
- 🎬 Video title and description analysis - Deep content understanding for XXX videos
- 📈 Video view count and engagement metrics - Performance indicators for XXX content
- 📅 Video upload and added dates - Timeline tracking for XXX video releases
- 🏢 Associated XXX channel information - Creator profiles and XXX video networks
🧠 XXX Content Intelligence
- 🏷️ Video categories and tags (official classifications) - Precise XXX content categorization
- 🎭 XXX Production information (amateur vs. professional) - XXX video quality classification
- 👥 Model attributes and featured performers - Comprehensive XXX performer data
- 🎥 Video quality indicators (resolution, duration) - Technical XXX content specifications
⭐ Video Quality Indicators
- 👍 Video like/dislike ratios - Community feedback on XXXX content
- ❤️ Video favorites count - User engagement with XXXX videos
- 💬 Video comment engagement - Discussion activity around XXX content
- 📊 Channel subscriber count - Creator popularity in XXX video space
🔧 Setting Up Your XXX Video Filtering Strategy
Here's how to build an XXX video filter system that actually works:
1. 🎯 Define Your XXX Video Niche Clearly
- What specific XXX content type are you targeting?
- Which XXX video categories align with your research?
- What XXX performer types or styles interest you?
2. 📏 Set XXX Video Quality Thresholds
- Minimum XXX video views (e.g., 10,000+ for popular XXX content)
- XXXX video like ratios (80%+ for well-received XXX videos)
- XXX video resolution standards (HD+ for quality XXX content)
- XXX video duration preferences (15+ minutes for substantial XXX videos)
3. 🏷️ Use XXX Video Category Filters
- Leverage official XXX video site categorization
- Focus on verified XXX content classifications
- Combine multiple XXX video categories for broader results
- Exclude unwanted XXX video types systematically
4. 👤 Apply XXX Performer Filters
- Consistent XXX content style through performer selection
- Verified XXX performers for quality assurance
- Specific XXX performer attributes matching your criteria
- XXX performer popularity metrics for content validation
5. ⏰ Time-Based XXX Video Filtering
- 🆕 Fresh XXX Content: Recently uploaded XXX videos (last 30 days)
- 📈 Trending XXX Videos: Currently popular XXX content
- 🏆 Classic XXXX Material: Established XXX video favorites
- 🔄 Regular XXXX Updates: New XXX content from followed creators
💡 Pro Tips for XXX Video Scraping Success
- 🎨 Combine Multiple Filters : Use XXX video categories + performer filters + quality thresholds
- 📊 Monitor XXXX Video Trends**: Track which XXX content types perform best
- 🔍 Refine XXX Keywords**: Test different XXX video search terms for better results
- 🎯 Focus on XXX Niches**: Specific XXX content types often yield better quality
- 📈 Track XXXX Video Performance**: Monitor engagement metrics for XXX content optimization
Step-by-Step: Scrape XXX Video Without Code by BrowserAct
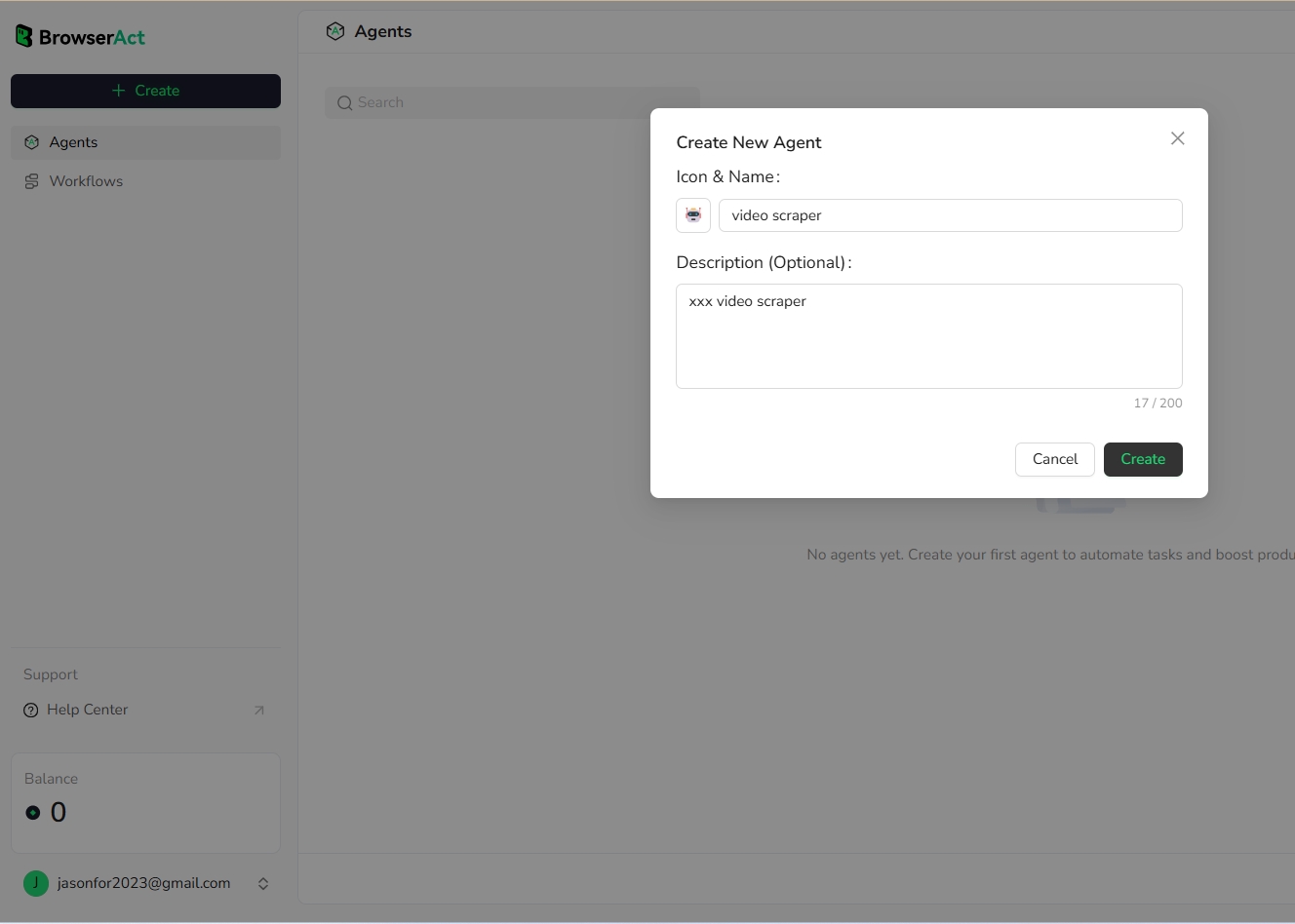
Step 1: Create a Video Scraper Agent
Open BrowserAct's dashboard → create new agent → name it "xxx video scraper"and describe it as you like
Agent Name: "xxx Video Content Collector" Description: "xxx video metadata extraction and content discovery assistant"
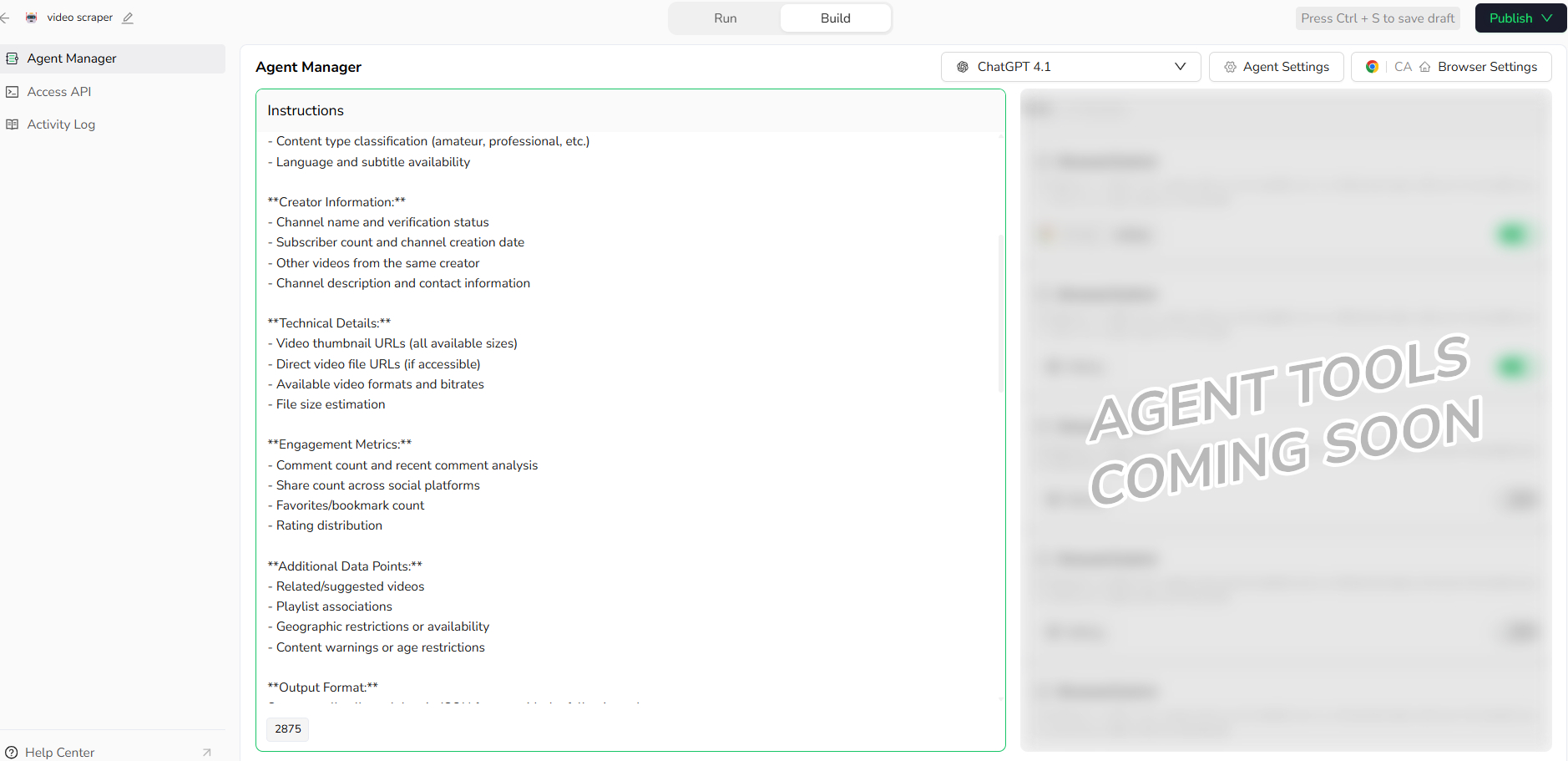
Step 2: Build Your Agent by Defining It
Define the agent's role, objectives, and boundary conditions:
Agent Role: xxx Video Content Discovery Assistant
Core Objective: Efficiently and safely obtain structured video metadata and content information
Data Quality: Ensure accuracy and completeness of collected video information
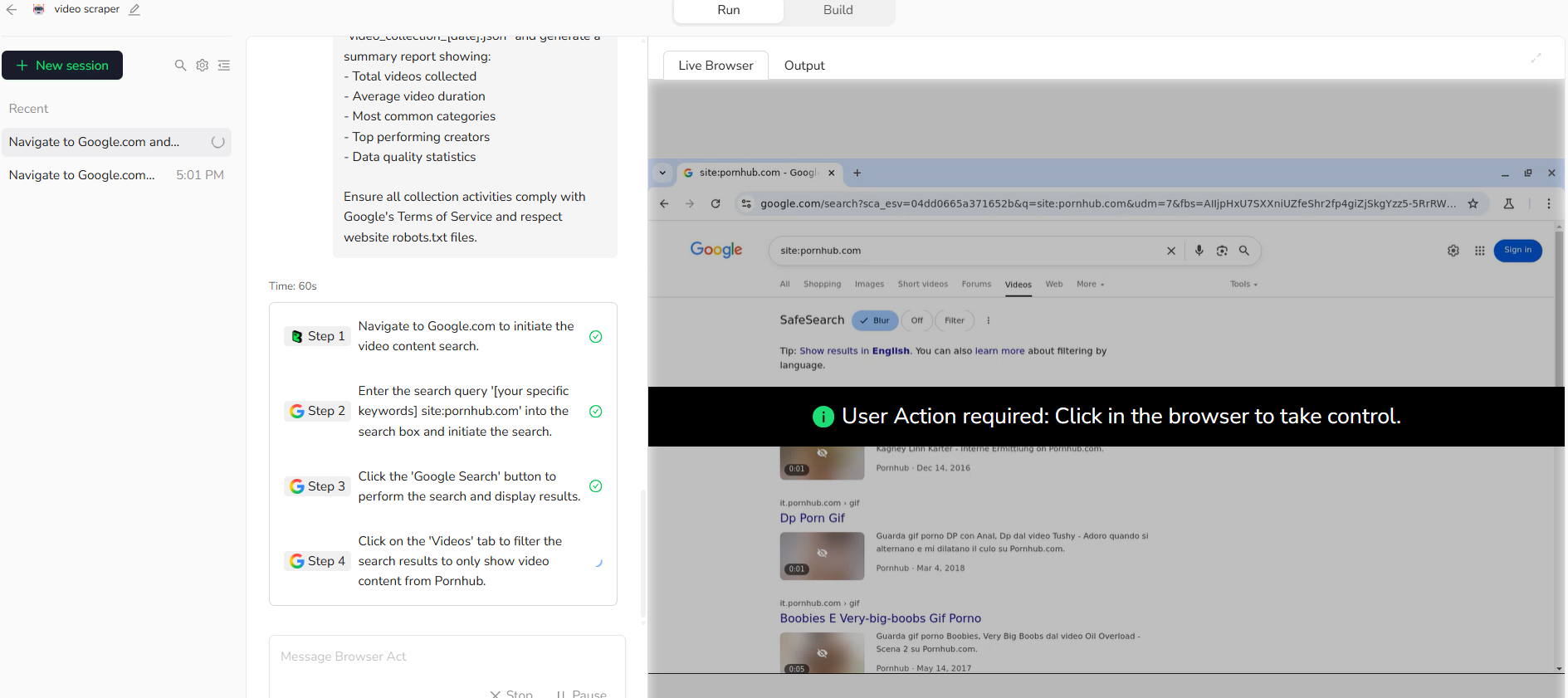
Step 3: Run Your Task by Chat with Your Agent
Send structured XXX video collection instructions as following:
For each XXX video, extract the following information:
1. Basic XXX Video Information:- XXX video title and description- XXX video duration (MM:SS format)- XXX video upload date- XXX video view count and engagement metrics- XXX video URL (direct accessible link)2. XXX Content Classification:- Primary XXX video category/genre- 3-5 relevant XXX video tags/keywords- XXX content type (amateur/professional)- XXX video language and quality indicators- XXX video niche classification3. XXX Creator Information:- XXX video channel/creator name- XXX performer verification status- XXX channel subscriber count (if available)- Other XXX videos from same creator- XXX performer attributes4. XXX Technical Details:- XXX video resolution and quality- XXX video thumbnail URL- XXX video file size estimation- Available XXX video formats
Please search for "[your specific niche] XXX video" and collect 20 high-quality XXX video results with minimum 1000 views and 5+ minutes duration. Save XXX video results in Excel format with clickable XXX video URLs.
BrowserAct Prompts for XXX Video Scraping: 5 Practical Examples
Here are five prompts you can use right now:
- Basic Video Collection "Go to [website], search for 'cooking tutorials', and collect all video URLs from the first 5 pages"
- Metadata Extraction "For each video found, save the title, duration, view count, and upload date to a spreadsheet"
- Selective Downloading "Download only videos that are longer than 10 minutes and have more than 5000 views"
- Category-Based Filtering "Browse the 'Education' category, exclude any videos with 'music' in the title, and save the results"
- Advanced Workflow "Search for multiple keywords ['fitness', 'workout', 'exercise'], remove duplicates, and organize by upload date"
The beauty of BrowserAct is that it handles the technical complexity while you focus on what you actually want to achieve.
📝 BrowserAct XXX data Collection Notes
When you use BrowserAct to scrape XXX videos, you'll get comprehensive metadata including video URLs. For actual XXX video downloading, BrowserAct provides the streaming links that you can process with tools like yt-dlp or similar downloaders.
BrowserAct's smart AI handles the tricky parts of XXX site navigation, so you don't need to worry about complex streaming protocols or site-specific quirks.
❓ FAQ Common Questions About XXX Video Scraping
Q: Can BrowserAct handle XXX video sites' anti-bot protection? A: Yes, BrowserAct's AI mimics human behavior and includes built-in anti-detection for XXX video platforms.
Q: How many videos can I scrape at once? A: BrowserAct provides 1000 credit for every new user everyd day.
Q: Is proxy usage required? A: While not required, using proxies is recommended for better reliability and to avoid IP blocks.
Q: How do I avoid getting my IP banned while scraping XXX videos? A: BrowserAct automatically manages request timing and includes proxy rotation specifically designed for XXX video site patterns.
Q: What XXX video metadata can I actually collect? A: BrowserAct can extract titles, descriptions, view counts, upload dates, categories, performer info, and technical details from XXX video pages.
Q: Can I set up automated XXX video monitoring? A: Absolutely! BrowserAct supports scheduled runs to monitor for new XXX video content matching your criteria.
📡 Integrations & Automation
Pornhub Video Scrapper (Downloader) can be integrated with multiple platforms, including:
- Make (formerly Integromat)
- Zapier
Top Video Scraping Tools and Software Recommendations
Let's be real - different tools work better for different situations. Here's my breakdown:
Open-Source Solutions: Scrapy, Selenium, and yt-dlp
yt-dlp: This is your Swiss Army knife for video downloads. It supports hundreds of sites and handles format conversion automatically. Perfect for one-off downloads or simple automation.
Scrapy + Selenium: When you need full control and don't mind coding. Scrapy handles the data extraction, while Selenium manages the browser interactions. Great for complex sites with heavy JavaScript.
Commercial APIs: Apify and Professional Services
Apify: Professional-grade scraping with pre-built actors. You pay for reliability and maintenance-free operation. Worth it if you're running a business and need consistent results.
Specialized Tools: JDownloader2 and FFmpeg Integration
JDownloader2: Excellent for batch downloads with a user-friendly interface. It remembers what you've downloaded and can handle most video sites without configuration.
FFmpeg: Essential for video conversion. If you're collecting M3U8 streams, you'll need this to convert them to MP4 for easy playback.
Legal Compliance and Risk Management in Video Scraping
Here's the part nobody likes to talk about, but you absolutely need to know.
Copyright and Fair Use Considerations
Just because you can scrape something doesn't mean you should. Most videos are protected by copyright, and downloading them without permission is technically illegal in many jurisdictions.
Fair Use might protect you if you're using videos for research, education, or criticism, but it's not a blanket protection. When in doubt, get permission or stick to public domain content.
Terms of Service and Website Policies
Every website has terms of service, and most explicitly prohibit scraping. You're technically violating these terms every time you scrape, which could result in:
- IP bans
- Legal action
- Account termination
Best Practices for Ethical Video Scraping
- Respect robots.txt: Check if the site allows scraping
- Don't overload servers: Use reasonable delays between requests
- Personal use only: Avoid redistributing scraped content
- Give credit: If you use content publicly, attribute the source
Conclusion: Building Your Video Scraping Strategy
Video scraping is powerful, but it requires the right approach. Start with your goals: Are you building a personal collection? Conducting research? Automating workflows?
Choose your tools based on your technical comfort level. If you're non-technical, start with BrowserAct
Most importantly, always consider the legal and ethical implications. The best scraping strategy is one that gets you the data you need while respecting content creators and platform policies.
Remember: the goal isn't just to collect videos - it's to collect the right videos efficiently and responsibly. With the right tools and approach, you can build a system tailored to your specific needs without the headaches.
Now go forth and scrape responsibly!

Relative Resources

AI Web Scraper Case Study: Automated News Intelligence

Case Study: Building an Amazon Product Data Extraction Agent

LinkedIn Monitoring With Top 6 Scraping Tools Explained

Social Monitoring Tools For Brand Protection
Latest Resources

Costco Wholesale Corporation Headquarters and Address

How to Research Instagram Creators with a Prompt—No Scraper Code

How to Monitor X Trends with a Prompt and a No-Code Cloud Bot
