How to Use the BrowserAct Extract Data Item Node

Learn BrowserAct's Extract Data Item sub-node for Loop List workflows. Extract structured fields from Items for forum analysis, e-commerce monitoring, and recruitment. Explore features, rules, examples, and FAQ to streamline data collection efficiently.
Function Overview
The Extract Data Item node is exclusive to the Loop List node, designed to extract structured data from the currently focused Item (e.g., title and price from a product card). It supports field-based extraction, with each Item processed independently. Data is aggregated across iterations. This sub-node simplifies data collection in workflows, enabling efficient list scraping without custom coding.
Key Features
- Field Extraction: Customize Item fields (e.g., title, description) for targeted, structured data pulling.
- Data Filtering: Supports setting filtering conditions for precise data collection.
- Loop Integration: Sequentially extracts from each Item, aggregating results for easy workflow export.
Applicable Scenarios
- Extracting post titles and authors from forum lists for content analysis.
- Pulling product prices and descriptions from e-commerce Items for price monitoring.
- Collecting location and salary details from job cards for recruitment databases.
Usage Rules
- Exclusive to Loop List; cannot be placed externally.
- At most, one Extract Data Item per Loop List.
- You can only extract fields within the visible region.
Operation Guide
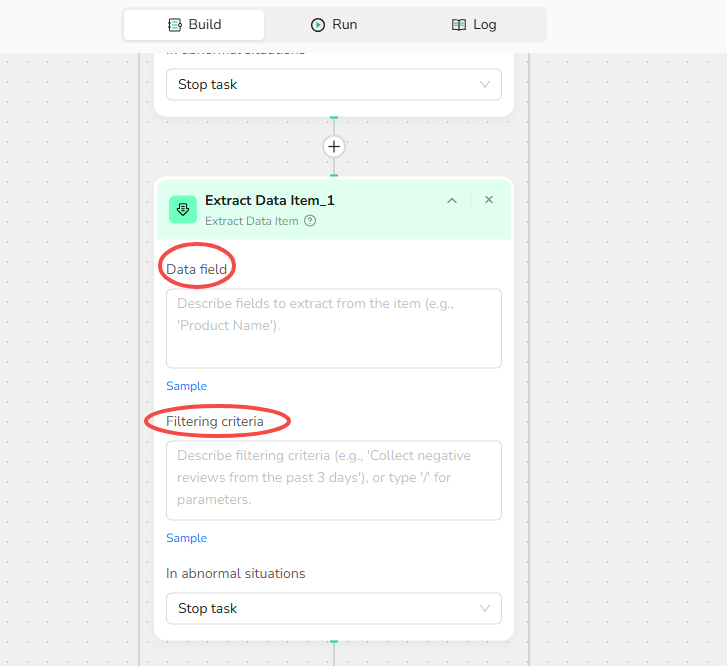
- Click the "+" icon inside the Loop List body to add the sub-node.
- Configure Extract Data Item settings:
- -Data Field: Extract the following fields from the post item: Post Title, Post Body, Publication Time, Likes Count. Use 'N/A' for any missing fields.
- -Filtering Criteria: Extract only data with publication time within the past 3 days.
Examples
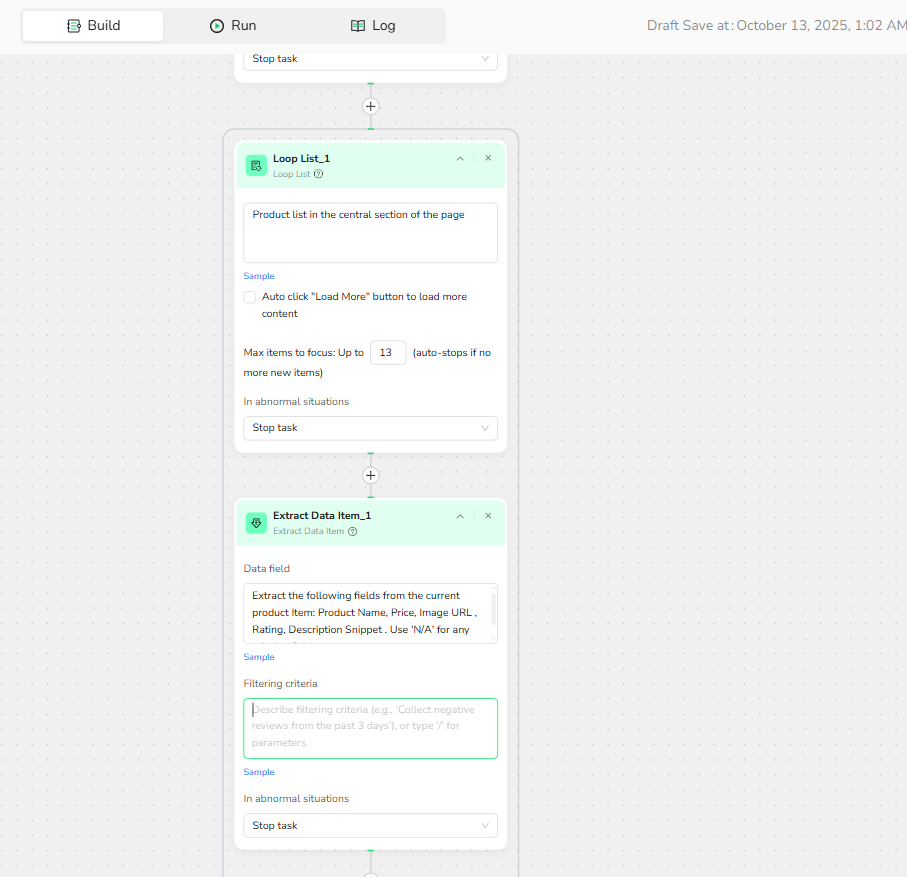
Case 1: Extracting Fields from Amazon Product Lists
1.Loop List Setup: Region = "Product list in the central section of the page"; Max Items = 13.
2.Add Extract Data Item: Prompt = "Extract the following fields from the current product Item: Product Name, Price, Image URL , Rating, Description Snippet . Use 'N/A' for any missing fields."
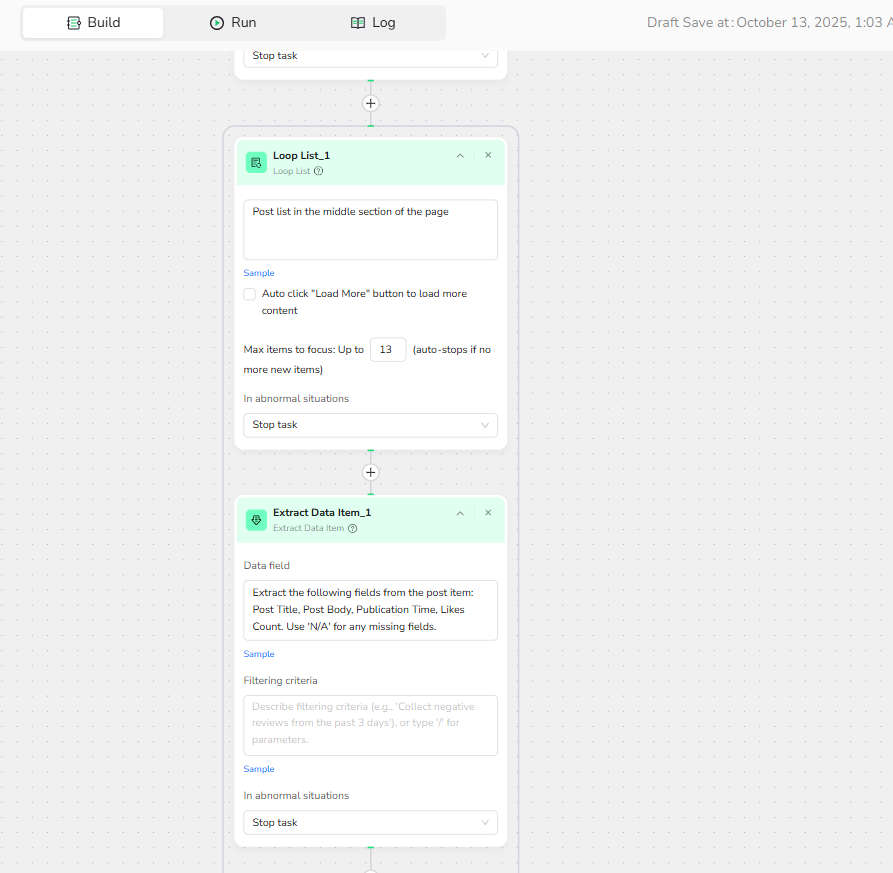
Case 2: Extracting Reddit Post Data for Analysis
1.Loop List Setup: Region = "Post list in the middle section of the page"; Max Items = 5.
2.Add Extract Data Item: Prompt = "Extract the following fields from the post item: Post Title, Post Body, Publication Time, Likes Count. Use 'N/A' for any missing fields."
FAQ
Q: How many fields can each Extract Data Item node extract?
A: It supports extracting fields within the visible region with no limit on the number of fields.
Q: What if fields are missing in an Item?
A: You can choose to default the output to 'N/A' to maintain format consistency.
Q: How many Extract Data Item nodes can be used at the same level?
A: Only one Extract Data Item node can be added per level.
Need help? Contact BrowserAct support or consult our documentation for more automation tips.
- Discord: [Discord Community]
- E-mail: service@browseract.com

Relative Resources

BrowseAct Professional Workflow Guide

BrowseAct Workflow is Now Live! More Accurate Data, Lower Costs!

How to Use BrowserAct's Credential Management Feature

Quick Start Guide- Build Agent for Task Optimization
Latest Resources

AI‑Powered Facebook Marketing: How to Automate Content Creation with ChatGPT and BrowserAct

How to Use the BrowserAct Click Element Item Node

How to Use the BrowserAct Loop List Node
