BrowserAct Extract Data Node | Beginner's Guide

Learn how to use BrowserAct's Extract Data node to pull structured information from any web page—no coding required. Whether you're tracking product prices, monitoring forum posts, or collecting job listings, this node lets you describe what you need in natural language and get clean, organized data every time. Explore setup steps, filtering options, and real examples to automate your data collection efficiently.
What is the Extract Data Node?
The Extract Data node helps you grab structured information from web pages quickly and reliably. Point it at a page, tell it what fields you want (like "product title, price, rating"), and it finds and organizes that data for you automatically. You can even add filters—say, "only posts from the last 7 days"—to focus on exactly what matters.
For example, you can extract all product names and prices from a search results page, or collect job titles, locations, and salaries from a recruitment site—all in one go.
When Should You Use It?
Use Extract Data when you need to:
- Compare prices — Pull prices, ratings, and descriptions from all products on a search results page
- Analyze content — Collect titles, authors, and publish times from forum or blog homepages
- Monitor jobs — Grab salary, location, and requirements from all visible job listings
- Track news — Extract article titles, summaries, and timestamps for sentiment analysis
- Gather product details — Pull complete specs, descriptions, and reviews from detail pages
Feature Comparison: Extract Data vs Extract Data Item
Extract Data:
This is an independent node that can be used anywhere in the workflow. It extracts data from the entire page or visible area. Each node executes only once, making it ideal for one-time extraction of all data on a page.
Extract Data Item:
This node can only be used inside a Loop List. It extracts data from the current focused single list item. The node executes repeatedly in the loop, once per item, making it perfect for extracting detailed information for each individual list item.
Easy to Remember:
Extract Data — Grab all data from the entire page (one-time execution)
Extract Data Item — Grab data from each item in a loop (repeated execution)
Key Features
- Natural Language Field Definition:Describe the fields you want in simple English, no coding required.
- Smart Data Filtering:Apply filtering conditions during extraction to get only the data you truly need.
- Seamless Workflow Integration:Extracted data outputs in structured formats like JSON, CSV, and can be directly passed to other nodes .
How to Set Up Extract Data Node (Step-by-Step)
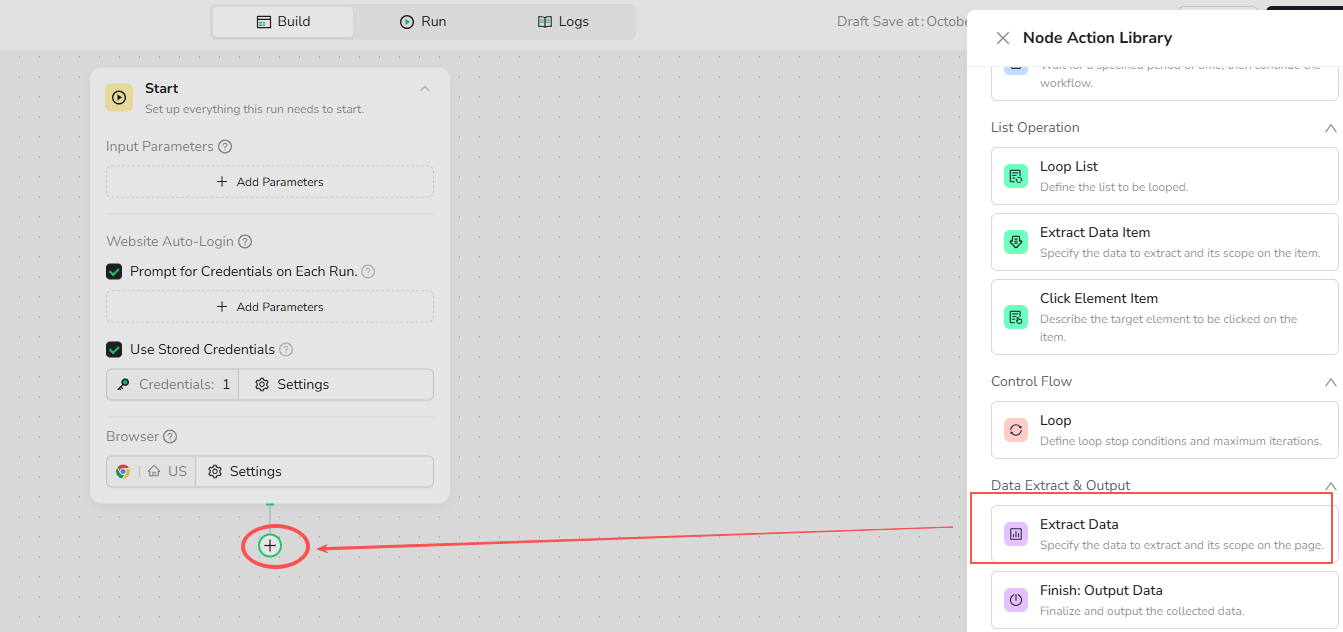
Step 1: Insert Extract Data Node
Click the + button in your workflow, then select "Extract Data" from the node library.
Step 2: Select Page Area Scope
Full Page:Extract all data from the entire page
Visible Area: Only extract data from the currently visible portion of the screen.
Tip: Use Full Page for faster, more complete extraction. Use Visible Area if the page is extremely long or dynamically loads content.
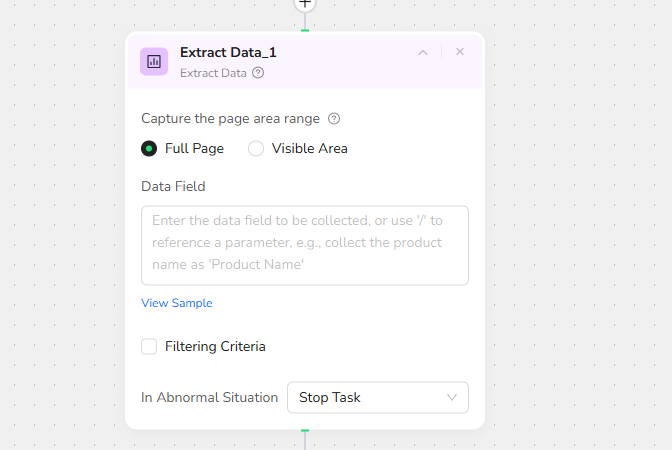
Step 3: Configure the Data Field
Describe the fields you want in your natural language:
Examples:
Extract the following fields from the recipe detail page: Recipe Name, Yield, Total Time, Print, Difficulty, Save To, Ingredients, Directions.
Step 4: Set Filtering Criteria (Optional)
Filter data before extraction to get only content that meets conditions:
Examples:
Only extract data published within the last 60 days
Only extract data published within the last 3 days
Using Parameter Reference:
Only extract data published within the last {{filter_days}} days
❌ Incorrect Examples (Avoid vague descriptions):
- Process comment data on the page
- Count the number of comments that meet conditions on the webpage
Note: Filtering criteria should be clear, specific, and describe explicit filtering rules.
Step 5: Configure Error Handling
Choose what happens when extraction fails:
Select "Stop Task" from the dropdown menu to stop the workflow if data cannot be extracted.
Step 6: Connect to Other Nodes
Typical workflow structure:
Visit Page → Extract Data → Output Data
Place Extract Data after navigation nodes (like Visit Page) and before data processing nodes (like Output Data ).
Example: Amazon Product Reviews Scraper
Before You Begin
This example extracts 30 reviews from a product's review page by ASIN.
Feel free to adjust this to your needs!
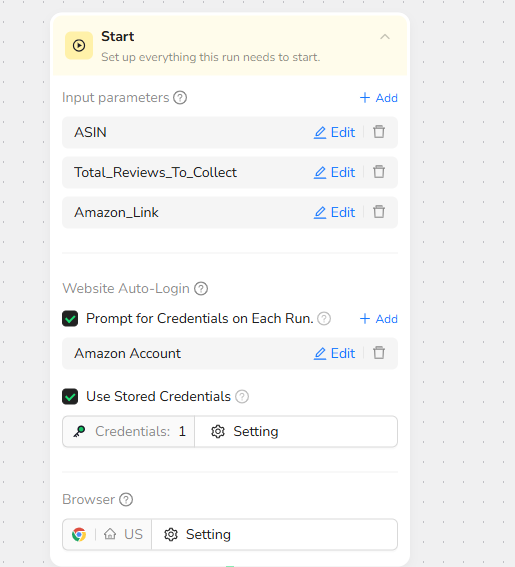
1.Start Node
Parameter Settings
ASIN: Product ASIN code, e.g., "B07TS6R1SF"
Total_Reviews_To_Collect: The number of reviews you want to extract, e.g., "30"
Amazon_Link: Amazon access link. This parameter cannot be changed
Website Auto-Login
Check: Prompt for Credentials on Each Run
Add your Amazon login credentials (username and password) to view more reviews
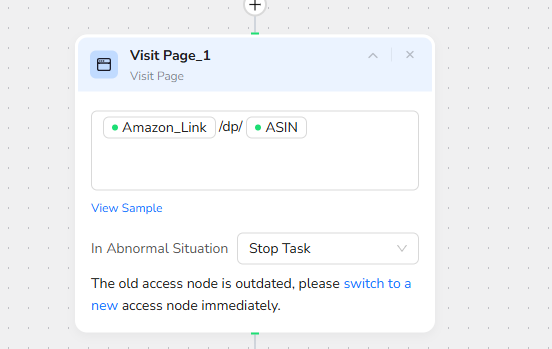
2.Add Visit Page
Navigate to the target website: Use "/" to reference the parameter Amazon_Link /dp/ASIN
3.Add Wait
Set wait time to 3 seconds to allow page to fully load
4.Add Click Element:
Click on the reviews link next to the star rating
5.Add Scroll to Element
Description:Scroll down to the View More Reviews button at the bottom of the reviews section above the top sellers in the Computers & Accessories section
6.Click Element:
Click the "View More Reviews Button" or see more reviews
7.Add Loop Node
Stop condition Description: Until the /Total_Reviews_To_Collect extraction is completed
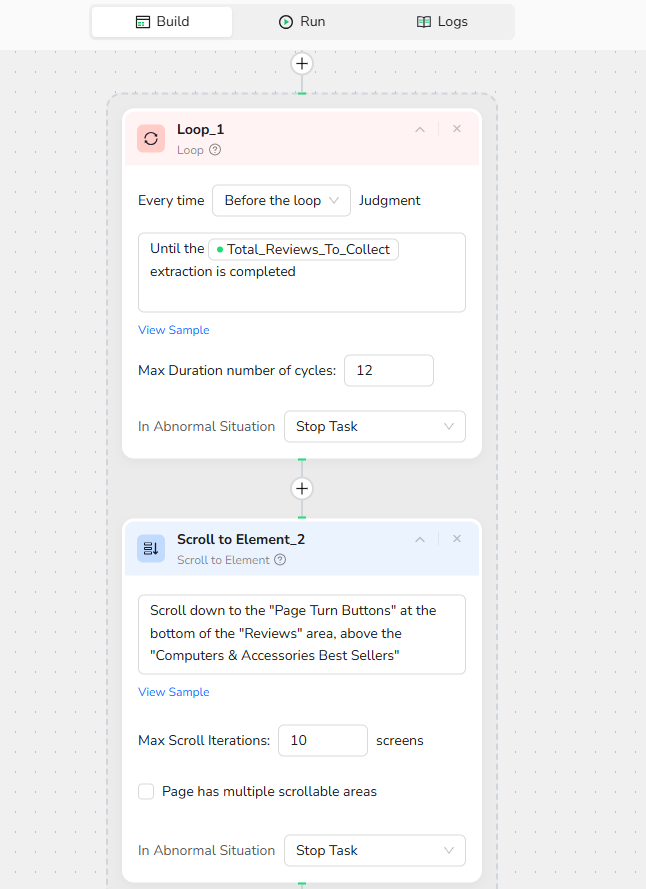
8.Add Scroll to Element
Scroll down to the "Page Turn Buttons" at the bottom of the "Reviews" area, above the "Computers & Accessories Best Sellers"
9.Extract Data
Data fields to extract:
- id: Incremental review count (starting at 1 and ending with the total number crawled)
- review_rating: Customer review rating (numeric only, e.g., 4 or 4.5)
- review_text: Customer review text
- date: Review date, in MM/DD/YYYY format
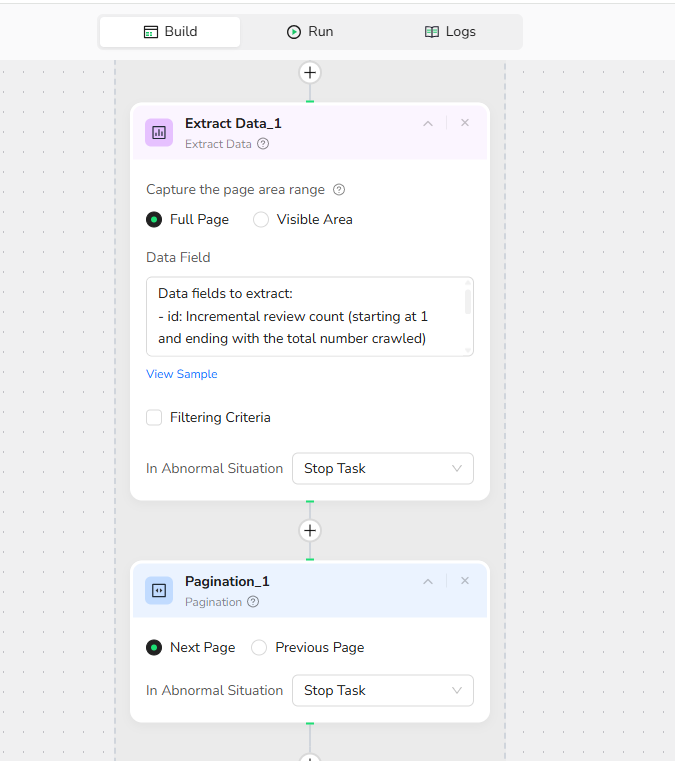
10.Pagination
Select pagination to go to the next page
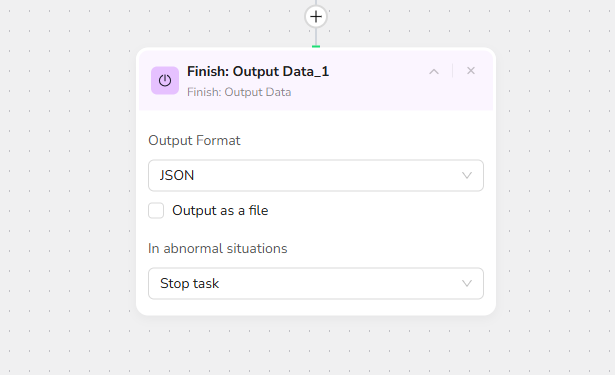
11 .Output Data
Choose the JSON output format. You can choose from multiple format options to suit your needs
Usage Rules and Best Practices
Important Rules
- Each Extract Data Node Executes Only Once
If you need to extract data from multiple pages, you should Place Extract Data node inside a Loop node - Choose Appropriate Area Scope
· Full Page — Use when all content is already loaded (faster, more complete)
· Visible Area — Use when page is very long or uses infinite scroll (avoid timeout) - Extract Complex Pages in Batches
When page structure is complex, use multiple Extract Data nodes to extract different sections separately rather than extracting all data at once.
Best Practices:
- Always describe fields clearly — The more specific you are, the better the results
- Use filtering to save time — Extract only recent or relevant data instead of everything
Quick Review
What Does Extract Data Node Do?
Extracts structured data from web pages (full page or visible area), outputs in JSON, CSV, and other formats.
Can I extract any fields from the page?
Yes—as long as the data is visible on the page, you can extract it
Can I use multiple Extract Data nodes?
Yes—you can use multiple nodes to extract different sections or apply different filters
Does it work with dynamic content?
Yes—but you may need to add a Wait node before extraction to ensure content loads fully
Need help?
· Check our documentation for more automation tips
· Join our Discord community for live support
· Email us at support@browseract.com

Relative Resources




Latest Resources

BrowserAct vs Skyvern: Open-Source Browser Agent vs Managed Workflow

BrowserAct vs Selenium in 2026: Is It Time to Move On?

BrowserAct CAPTCHA Handling vs 2Captcha vs CapSolver: Real Cost Comparison
