How to Accurately Monitor Subreddits of Reddit Without Code

Discover how BrowserAct, an AI-guided no-code browser automation tool, simplifies Reddit data extraction. Learn to effortlessly scrape posts, comments, and user profiles for insights and analysis without writing any code.
Reddit is a network of communities built on shared interests, passion, and trust. It's home to some of the most open and authentic conversations on the internet. Every day, users submit, vote, and comment on topics that matter most to them. With over 100,000 active communities and approximately 91 million daily active unique visitors, Reddit is one of the largest sources of information online.

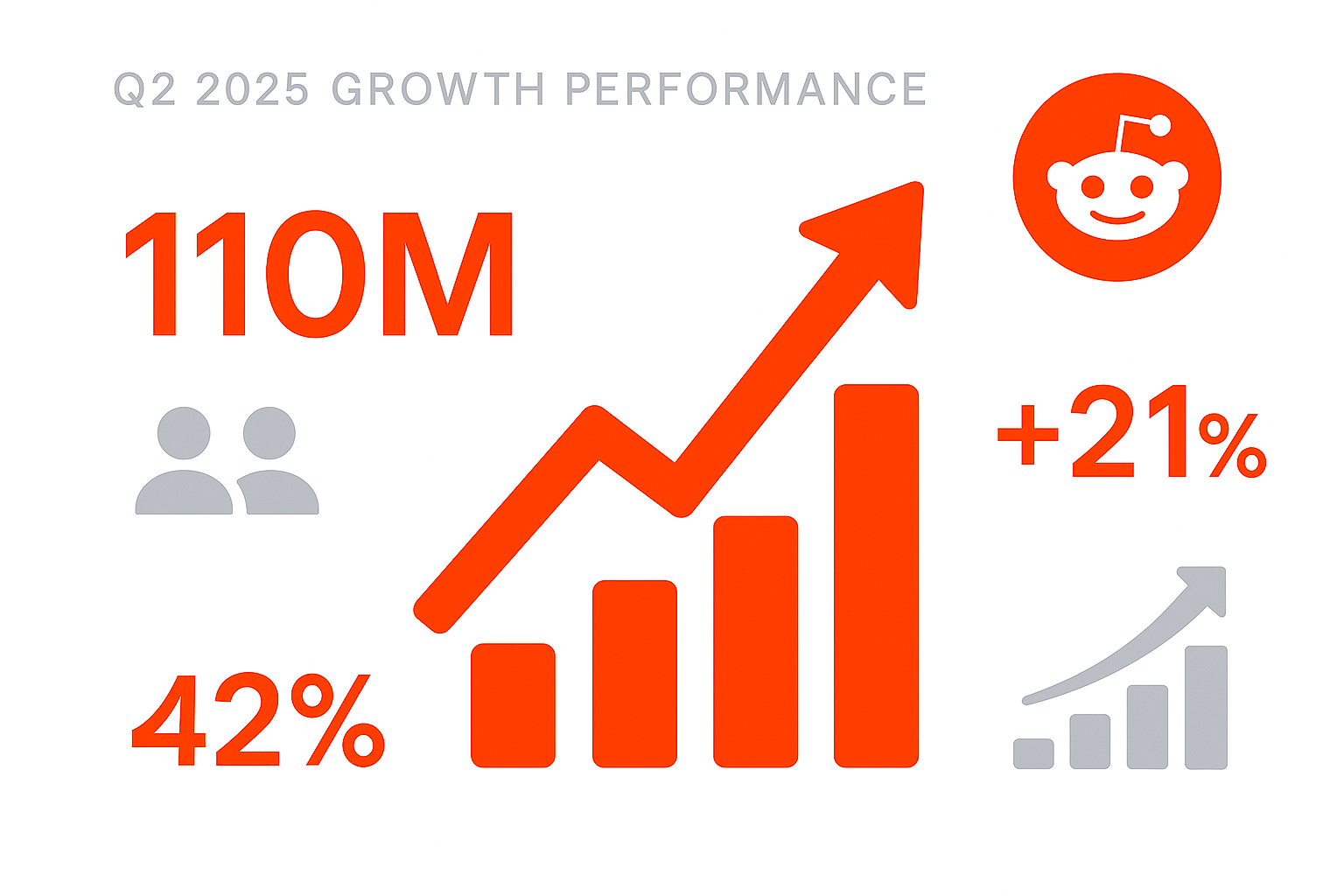
According to its Q2 2025 earnings report, Reddit's performance has shown outstanding growth, with its global traffic steadily rising. The platform's quarterly global DAUs increased to 110 million, a 21% year over year increase. Reddit remains a premier channel for information discovery and distribution. Countless users turn to Reddit for insights, while many companies use it to test new products and gather authentic user feedback.
While Reddit holds a massive amount of data, accessing it can be challenging. Reddit often limits data access for users who are not logged in, making it difficult to find a reliable data collection method. Many people lack a programming background, and current AI tools often struggle to accurately extract the specific data required.
We have found a solution that uses a no code visual interface to enable unlimited web scraping on Reddit. You can capture posts, comments, communities, and user profiles. You can also limit the scraping process by the number of posts or entries and extract the dataset in multiple formats.
Let me walk you through a specific example.
"I need to scrape the 30 latest posts and their URLs from https://www.reddit.com/r/AskReddit/"
The tool I use for this is Browseract, an AI guided no code browser automation tool that allows me to build various data scrapers.
To ensure the task's precision and reliability, I use the workflow module for orchestration. I first tested this by building a workflow to scrape the top posts from a specific subreddit and automatically save them as a CSV file. The result was excellent.
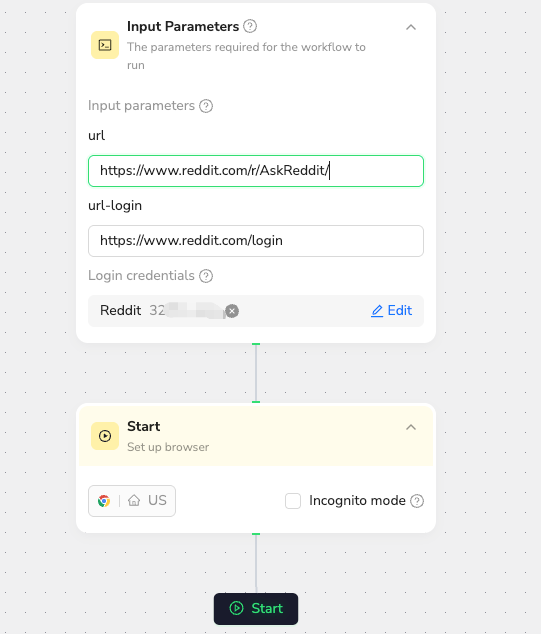
Here is my Reddit scraper workflow interface.

Here are the results.
Create and name a new workflow.
Start building the workflow by configuring the basic application nodes.
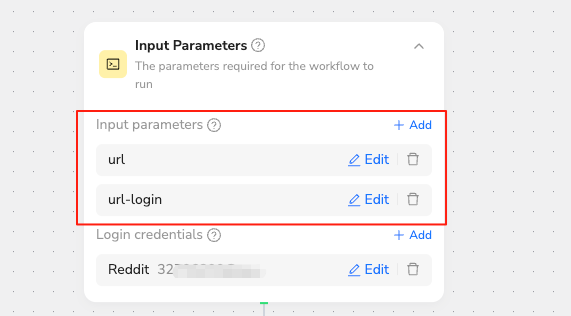
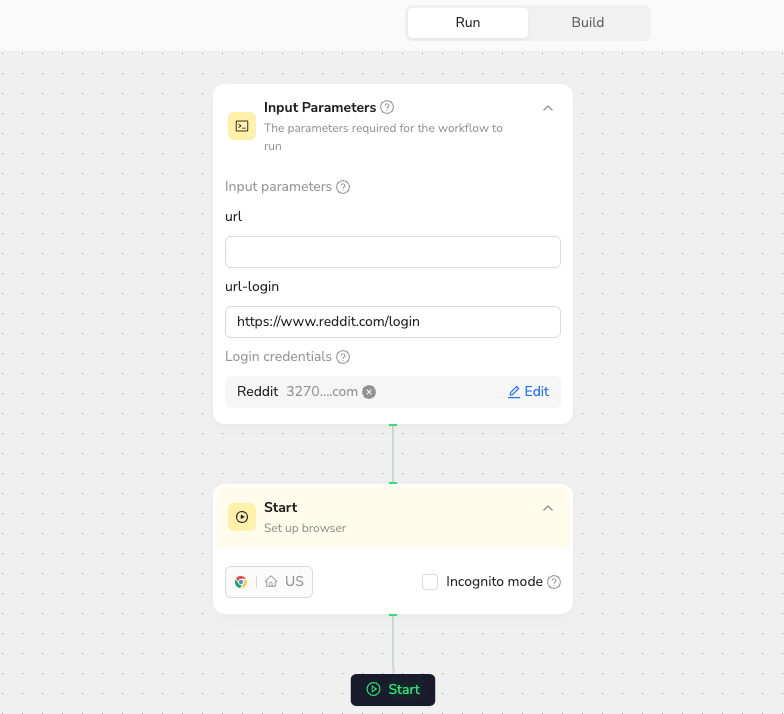
This is a reference node for the target URL. It can be set to a fixed value or configured as a variable that can be changed with each run.
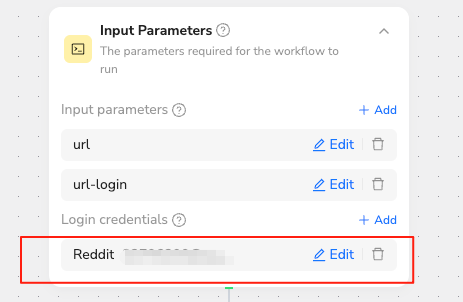
This is for my Reddit account. After I fill in my login details, it will automatically complete the sign in process for me.
Start building the workflow.
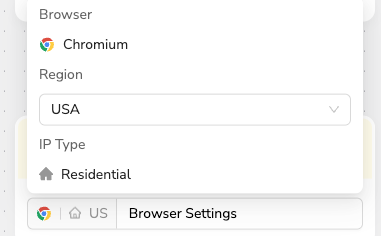
I've selected a US IP address because I want to see the content that users in the United States see. Reddit's recommendation system often shows different content based on your country.
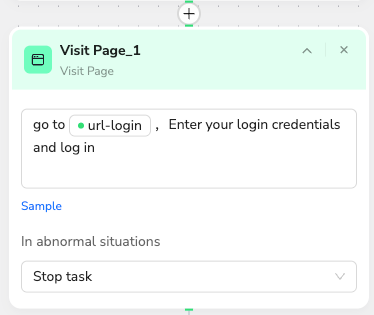
I'll start by having the workflow navigate to Reddit and log in automatically. This minimizes wait times for the data collection step. I can directly reference the parameters I configured in Step 1 to reduce manual input.
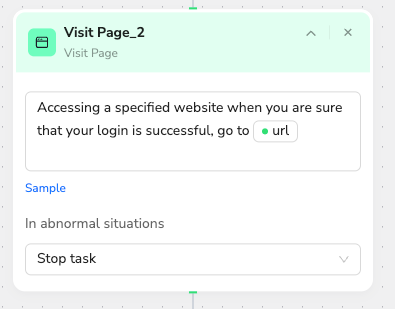
Next, the workflow will navigate to the target subreddit page. I can paste any subreddit URL here when the workflow runs.
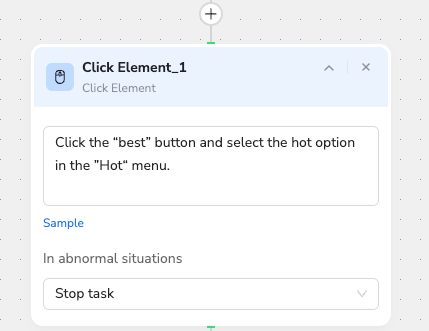
Use a click node to trigger the "hot" button, displaying all the posts in that section.
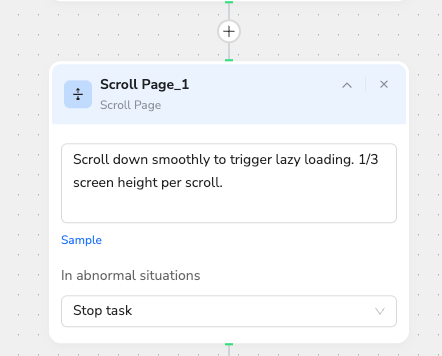
Use a scroll node to automatically scroll the page and collect all the displayed data.
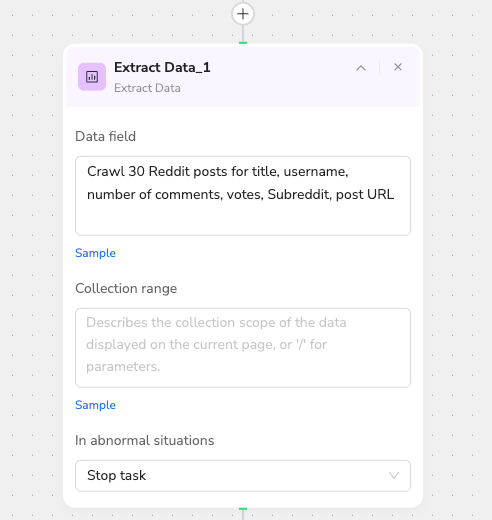
The Extract Data node pulls and categorizes the data based on my specifications.
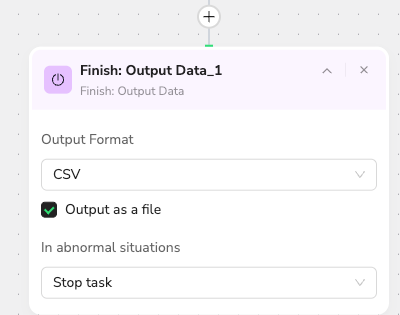
I need to save it as a CSV to use for other work.
Publish my workflow to make it a ready-to-use tool.
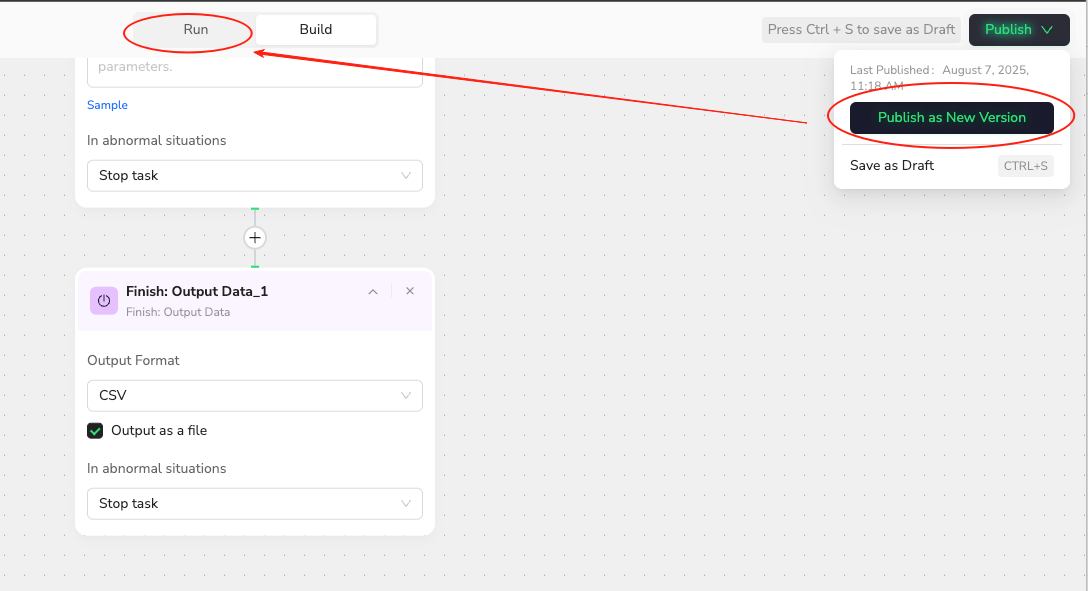
After clicking "Publish," I can run my workflow from the "Run" tab. Of course, I can also test it before publishing. Now, I can scrape data from any subreddit just by entering its URL in the input field.
And just like that, I get the CSV file I showed at the beginning, containing all the data I needed. I didn't use a single line of code. All I had to do was plan my scraping strategy and turn that plan into an executable, automated workflow. This has saved me a tremendous amount of work. Now I can use the latest data from Reddit to write my analysis, gather insights, and apply them to my work. Best of all, the entire process used virtually no credits.
BrowserAct can also be used with n8n. I will continue to configure its powerful and easy-to-orchestrate scraping capabilities. Stay tuned for my next results

Relative Resources

How to Find Best Selling Products on Amazon in 2025

How to Scrape Google News via No-Code News Scraper

Why Use a Reddit Scraper? 12 Reasons for Market Intelligence

How to Find Leads on Yellow Pages For Your Business with BrowserAct
Latest Resources

OpenCode Permissions for Browser Automation Safety

OpenCode Skills Browser Automation: Reusable Web Workflows

Kimi Code Token Usage: Why 1M Context Still Needs BrowserAct
