Amazon CAPTCHA Bypass Guide: Why Every Scraper Gets Blocked (And How to Actually Fix It in 2026)

"Pull the top 100 best-selling wireless earbuds on Amazon. Get me prices, ratings, review counts."
Your scraper starts fine. Product 1, 2, 3... data flowing in. Then around product 47, the responses change:
``html`
Sorry, we just need to make sure you're not a robot.

Your scraper is cooked. Every subsequent request gets the same CAPTCHA page. Your IP is flagged, your session is burnt, and you're back to copying product pages by hand.
This is the Amazon scraping experience most developers hit within their first hour — and most "amazon captcha bypass" guides online either sell you a $50/month solver service that breaks at scale, or walk you through Puppeteer setups that last two weeks before Amazon updates detection. This piece covers AWS WAF (the actual name of Amazon's CAPTCHA system), why the solver-API approach has a scaling ceiling, and the one architecture that doesn't trigger the CAPTCHA at all.
Quick answer: Amazon uses AWS WAF Bot Control + image/token CAPTCHAs. Standard bypass methods — solver APIs (2Captcha, CapSolver), stealth plugins, residential proxies — work at low volume but break at scale. The only durable 2026 approach is real-browser takeover: run automation inside your actual Chrome with real session history, so AWS WAF never scores you as a bot.
- 1Amazon CAPTCHAs are AWS WAF Bot Control challenges — a multi-layer risk-scoring system, not a simple puzzle. Most "amazon captcha bypass" guides miss this name and the two types (image-based vs token-based).
- 2Solver services (2Captcha ~$1/1,000, CapSolver ~$0.80/1,000) work on image CAPTCHAs but can't touch the invisible token challenges; they also can't clear the underlying risk score, so CAPTCHAs keep firing.
- 3Stealth plugins + residential proxies + solver fallback gets you to ~85% success at ~$0.40 per 100 products — but has weekly maintenance overhead as Amazon updates detection.
- 4The silent failure mode nobody mentions: AWS WAF serves cloaked content (200 OK, stale data) to scrapers that pass the fingerprint threshold partially. Random-sample your output to catch it.
- 5Real-browser takeover (using your daily Chrome with accumulated session history) achieves ~98% success with zero maintenance — because AWS WAF's risk score was built on real browsing behavior, not puzzle-solving.
Why Amazon Hates Scrapers (And Why AWS WAF Exists)
Amazon has real money on the line when scrapers run. Three reasons they invested heavily in AWS WAF Bot Control:
1. Competitor pricing intelligence — Walmart, Target, Shein, Temu all run price trackers against Amazon's catalog. Amazon would rather they didn't.
2. Fake review detection — sellers buying review farms scrape top-rated listings to pattern-match fake reviews to legitimate ones.
3. Compute cost at scale — aggressive scrapers make millions of requests; that's real AWS money.
As a result, amazon.com, amazon.co.uk, and all regional Amazon sites run AWS WAF (Web Application Firewall) with Bot Control managed rules. This isn't just a CAPTCHA popup — it's a multi-layer scoring system that decides whether to serve real data, challenge with a CAPTCHA, or silently return cloaked content.
The Two Types of Amazon CAPTCHA
Almost every top guide skips this distinction. It matters because different solvers handle different types:
Type | When it appears | Visible? | Solver compatibility |
Image-based AWS WAF CAPTCHA | High-risk scraping patterns | Yes — 3x3 grid, pick-the-images | 2Captcha, Anti-Captcha, CapSolver handle it |
Token-based AWS WAF challenge | Ambient browser fingerprint score below threshold | Invisible | Most solver APIs fail; requires browser-level token generation |
If your scraper only knows how to handle image CAPTCHAs, it will fail silently on token challenges.
What Triggers AWS WAF on Amazon

Amazon's detection uses a layered stack. Miss any one of these and the CAPTCHA fires (or worse — you get cloaked data):
Signal | What AWS WAF Checks | Typical Trigger |
IP reputation | Datacenter vs residential, AWS IP ranges blocklist | AWS EC2, GCP, DigitalOcean IPs, public proxy pools |
Request rate | Requests per minute per IP/session | 50+ product pages in a 60-second window |
User-Agent | Consistency with TLS, HTTP/2 settings, Accept headers | Python requests default UA, stale Chrome versions |
TLS fingerprint | JA3/JA4 hash against known Chrome/Safari builds | requests/httpx TLS, custom Go clients |
Behavioral pattern | Cookie acceptance, referer chains, page-to-page flow | Hitting product URLs directly without category browsing |
Browser fingerprint | Canvas hash, WebGL, installed fonts, screen dimensions | Headless Chrome defaults, Selenium WebDriver, Puppeteer |
Session continuity | Same cookies across requests, realistic dwell times | Fresh session every request |
A naive Python requests scraper typically gets 10-30 products in before blocking. Playwright stealth can reach 100-300. Real-browser takeover can sustain 500-2,000/day indefinitely.
From r/RealAmazonFlexDrivers — a thread titled "Endless Captcha — Solutions?" has dozens of drivers complaining the Amazon Flex app loops them through CAPTCHAs forever. That's AWS WAF's risk score saying "something is off about this device" — exactly what scrapers hit, at machine scale.
The 5 Approaches Developers Try (And Real Pricing for 2026)
1. CAPTCHA-Solving Services (2Captcha, Anti-Captcha, CapSolver)
How it works: Detect the AWS WAF CAPTCHA page, ship the image (or token challenge parameters) to the solver's API, get the answer back, submit it.
Real 2026 pricing for Amazon:
Service | Image CAPTCHA | Token Challenge | Notes |
2Captcha | $0.99 / 1,000 solves | $2.99 / 1,000 | Well-documented Amazon WAF support |
Anti-Captcha | $0.50–$2 / 1,000 | Supported via AmazonTaskProxyless | Lower success rate without proxy |
CapSolver | $0.80 / 1,000 | $2.50 / 1,000 | Browser extension + API integration |
js
const solution = await captchaSolver.aws({
websiteURL: page.url(),
challengeScript: extractedChallengeScript,
captchaScript: extractedCaptchaScript,
});
await page.evaluate((answer) => {
document.querySelector('input[name=captcha]').value = answer;
document.forms[0].submit();
}, solution.token);
`
Why it breaks at scale: Solving the visible CAPTCHA doesn't remove the underlying AWS WAF risk score. Your IP/session was flagged; after you solve it, the next 2–3 requests might work, then another CAPTCHA fires, then a full 403. Each solve costs money and time (~10–30s latency per solve). At 10,000 requests/day, that's a $30+/day API bill just for CAPTCHAs — before proxy costs.
When it still works: Low-volume one-offs. 50 products a day? Fine. 5,000? Losing battle.
2. Stealth Plugins + Puppeteer/Playwright
How it works: Patch your headless browser to hide obvious automation signals —
navigator.webdriver = false, canvas noise injection, realistic plugin list. Most popular: puppeteer-extra-plugin-stealth, playwright-extra.
Cost: Free, open-source.
Why it partially works: Stealth plugins handle shallow checks. AWS WAF's deeper checks — WebGL hash consistency, audio context fingerprint, font enumeration, mouse movement patterns — require stealth maintenance that the open-source community usually lags on by 1–3 weeks. You work for two weeks, Amazon rolls a detection update, you break for one, community patches, you work again. Repeat.
The honest failure mode from r/webscraping: "I built an Amazon scraper in Puppeteer with puppeteer-stealth. Worked for 3 weeks. Then Amazon changed their detection and I spent 2 days patching the config. Two weeks later, same thing. I gave up."
3. Residential Proxy Services (Bright Data, Oxylabs, IPRoyal)
How it works: Route every request through rotating residential IPs — real home internet addresses AWS WAF can't blacklist without blocking real customers.
Pricing: $6–$20 per GB. At ~5 MB per Amazon product page (with images), that's $0.03–$0.10 per 100 products in proxy fees alone.
Why it partially works: Residential IPs dramatically reduce CAPTCHA rate (from ~20% success → ~80%). But proxies alone don't fix TLS fingerprint, browser fingerprint, or behavioral pattern signals. Combined with stealth plugins, you get to ~90%, maintained weekly.
When it works: Medium volume where you can afford ~$30–$100/day in proxy + solver fallback.
4. Amazon's Product Advertising API (PA-API 5.0)
How it works: Go official. Register as an Amazon Associate, qualify for API access.
Why it partially fails:
- Requires active Amazon Associates account with recent qualifying sales.
- Rate limit starts at 1 request per second, scales with revenue.
- Returns limited data: no price history, no review bodies, no best-seller rank changes over time.
- If you don't generate sales within 30 days, access is revoked.
When it works: You're an Amazon affiliate. Use PA-API for basics, scraping only for what the API doesn't expose.
5. Real-Browser Takeover
How it works: Instead of running automation in a fresh headless Chrome, take control of your daily Chrome — the one already logged into amazon.com, with months of browsing history, real cookie age, and a TLS fingerprint AWS WAF has been seeing for months.
Why it works when others fail: AWS WAF's risk score is built from cumulative behavior over time. A freshly-launched headless Chrome has zero history; the score starts neutral and quickly goes negative with any mechanical pattern. A Chrome you've used for a year has a deeply positive reputation. The agent inherits that reputation.
Cost: Free locally. Only pays LLM tokens for the AI agent's reasoning (~$0.05 per 100 products).
When it works: Essentially always for medium-volume scraping. The 3 failure modes:
- Sites requiring a fresh anonymous view (not relevant for Amazon)
- Running thousands of parallel sessions from one machine (out of scope for local)
- Amazon Locker / Seller Central admin actions that trigger explicit re-challenge (rare)
Benchmark: 100 Amazon Products Across 5 Approaches
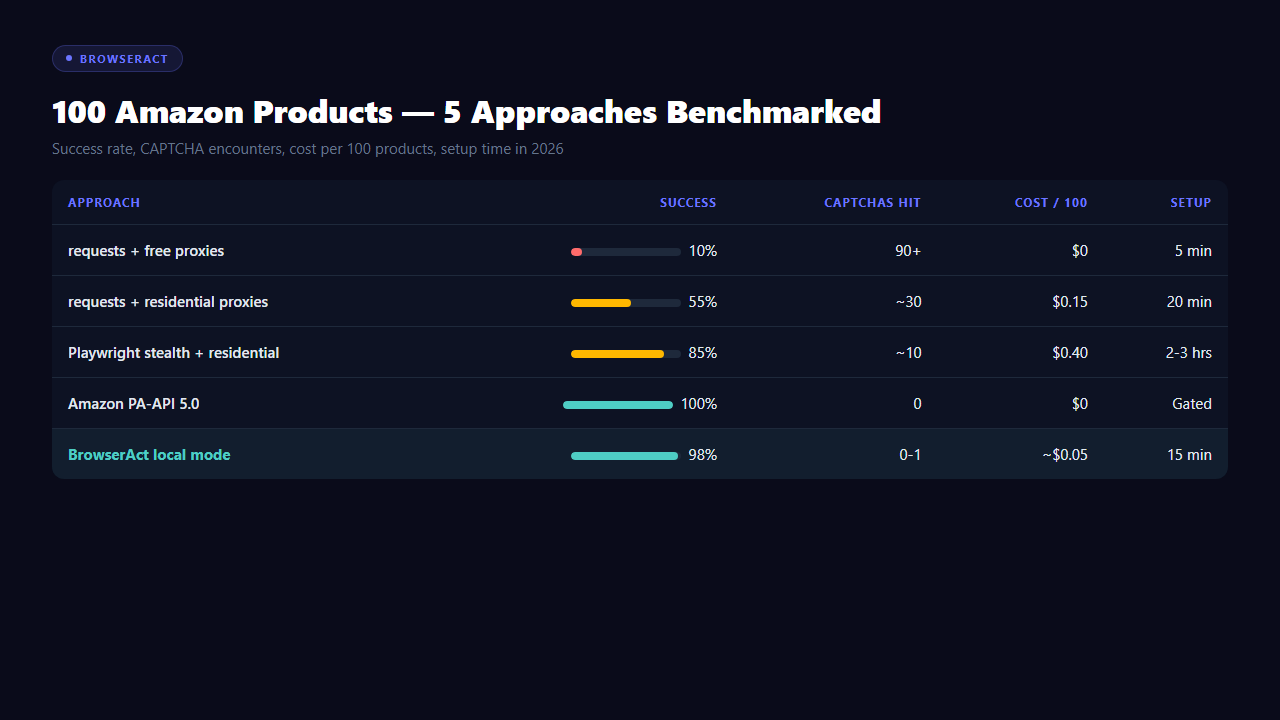
Ran identical extraction tasks across five approaches. Data: product title, price, rating, reviews, seller, stock status.
Approach
Success rate
CAPTCHA encounters
Cost per 100
Setup time
Maintenance
requests + free proxies
~10%
90+
~$0
5 min
Daily
requests + residential
~55%
~30
$0.15
20 min
Weekly
Playwright + stealth + residential
~85%
~10
$0.40 (proxy + solver fallback)
2–3 hrs
Weekly
PA-API 5.0
100%
0
$0
Requires affiliate status
None
BrowserAct local mode
~98%
0–1
~$0.05 (LLM tokens)
15 min
None
The surprising number isn't success rate. It's maintenance cost — the hidden treadmill that makes stealth configs break every week. Real-browser takeover has no treadmill because you're not faking anything.
BrowserAct
Stop getting blocked. Start getting data.
- ✓ Stealth browser fingerprints — bypass Cloudflare, DataDome, PerimeterX
- ✓ Automatic CAPTCHA solving — reCAPTCHA, hCaptcha, Turnstile
- ✓ Residential proxies from 195+ countries
- ✓ 5,000+ pre-built Skills on ClawHub
The Silent Failure Mode Nobody Writes About
Most amazon-captcha-bypass guides assume the visible CAPTCHA is the only failure mode. It isn't. AWS WAF has three responses:
1. Serve real content (happy path)
2. Show CAPTCHA (what guides cover)
3. Serve cloaked content (what scrapers don't notice)
Cloaked content looks like a normal product page but contains stale prices, placeholder reviews, or zeroed-out stock. Your scraper receives HTTP 200, parses clean HTML, stores data — and the data is wrong. You won't notice until a customer or client flags the output.
How to detect cloaking:
- Random-sample 1% of scraped products against manual browser views
- Check for timestamp/nonce markers on the page
- Compare price distribution against recent Keepa data — if everything looks flat or suspiciously uniform, you're being cloaked
Real-browser takeover doesn't hit cloaking, because the browser passes fingerprint checks that gate cloaking.
The Legal Note Every Guide Should Include
Scraping publicly-viewable Amazon product data is generally legal (hiQ Labs v. LinkedIn, 2022 precedent on public web data). But:
- It violates Amazon's ToS — they can ban your accounts and IPs
- Do NOT scrape logged-in data (order history, Seller Central, account info) — that's CFAA territory
- Do NOT scrape for use in fake reviews or marketplace manipulation — federal action has been taken
- Keep your scraping within what a normal user could do manually — bulk-extracting millions of SKUs crosses into grey territory
For competitive price intelligence on public listings, you're in the clear legally. Just don't expect Amazon to help you.
The Practical 2026 Setup (15 Minutes)
Skipping the Puppeteer stealth maze, here's the minimum viable real-browser takeover:
1. Install BrowserAct CLI —
uv tool install browser-act-cli --python 3.12
2. Connect to your daily Chrome —
3. Verify no CAPTCHA on cold load — navigate any product page, confirm it renders normally
4. Write your extraction prompt — natural language, not CSS selectors
5. Add human-paced delays — For production workflows, skip the DIY and use templates: BrowserAct's Amazon Bestsellers Scraper handles pagination, dedup, and daily diffs out of the box. The Amazon Product Search API wraps the whole thing as a single API call if you'd rather not touch browser code.
For the first run, stay under 100 products to confirm no CAPTCHA pattern. Scale up once verified.
Conclusion
Most Amazon CAPTCHA bypass guides in 2026 are still teaching puzzle-solving as if it's 2020. AWS WAF is not a puzzle layer — it's a reputation scoring system that runs for every request, independent of whether a CAPTCHA is ever shown. Solvers, stealth plugins, and residential proxies are bandaids on symptoms.
The durable 2026 answer is to stop pretending to be a real browser and just use a real one. Tools like BrowserAct make this a 15-minute setup. For anyone tired of maintaining stealth configs that break every Cloudflare update and burning solver credits that don't scale, the switch is worth an afternoon.
Amazon's CAPTCHA wasn't built to stop you. It was built to stop bots pretending to be you. Stop pretending, and the wall goes away.
Automate Any Website with BrowserAct Skills
Pre-built automation patterns for the sites your agent needs most. Install in one click.
Frequently Asked Questions
What is AWS WAF CAPTCHA on Amazon?
AWS WAF (Web Application Firewall) Bot Control is the system Amazon uses to score and challenge automated traffic. It can show image CAPTCHAs, invisible token challenges, or silently serve stale content.
How much does 2Captcha charge for Amazon CAPTCHAs?
~$1 per 1,000 image CAPTCHAs, ~$3 per 1,000 token challenges. Solving doesn't remove the underlying risk score, so you'll still hit CAPTCHAs repeatedly.
Can free proxies bypass Amazon's CAPTCHA?
No. Amazon blacklists datacenter and free-proxy IPs aggressively. Free proxies trigger CAPTCHAs on the first request in most cases.
Is scraping Amazon legal?
Scraping publicly-viewable product data is generally legal (hiQ v. LinkedIn precedent) but violates Amazon's Terms of Service. Your accounts and IPs can be banned. Do not scrape logged-in data.
How many Amazon products can I scrape per day without getting blocked?
Naive Python requests: 20–50 before block. Playwright + stealth + residential: ~500–1,000/day. Real-browser takeover: 500–2,000/day sustainable.
Does Amazon's PA-API work without sales?
No. You need an Amazon Associates account with qualifying recent sales. Access is revoked if you don't generate sales within 30 days of API use.
What's the difference between image-based and token-based AWS WAF CAPTCHA?
Image-based shows a 3x3 grid you pick from — solvable by 2Captcha/CapSolver. Token-based is invisible; AWS WAF scores your browser silently and blocks without visible puzzle. Most solver APIs can't handle token challenges.
Can AI agents scrape Amazon without triggering CAPTCHAs?
Yes, when running inside a real browser with established session history. Agents in fresh headless browsers trigger CAPTCHAs just like any scraper.
Will Amazon ban my account for using a browser automation tool?
Local-mode automation that respects human browsing rhythm (2–5s delays, 100–500 products/day) is indistinguishable from manual shopping and rarely triggers action. Running bulk scrapers while logged in is risky.

Relative Resources

Claude Code Browser Automation: Run Protected Web Tasks

Codex Browser Automation: Add a Reliable Web Execution Layer

Windsurf Browser Automation: Test Logged-In Apps

OpenCode Browser Automation: Run Multi-Model Web Tasks with BrowserAct
Latest Resources

OpenCode Permissions for Browser Automation Safety

OpenCode Skills Browser Automation: Reusable Web Workflows

Kimi Code Token Usage: Why 1M Context Still Needs BrowserAct
