
Indeed Job Scraper
Indeed Job Scraper lets you effortlessly collect and export job data, including Job Title, Company Name, Salary, and Salary Unit, from the web in just a few clicks—no coding needed!

Brief
What Does BrowserAct Indeed Scraper Do?
Automatically extract Indeed job posting data and associated details with our powerful Indeed scraper tool. Capture job titles, company names, locations, salary ranges, job descriptions, required skills, posting dates, and more from any search results page or company profiles. Enjoy flexible filtering and output options for comprehensive job market analysis—no coding required.
Our Indeed scraper is built for seamless integration with automation platforms like Make.com, making it ideal for ongoing monitoring and data extraction tasks.
Key Features of Indeed Scraper
- Customizable Parameters: Adjust Datalimit to control extraction depth (e.g., 10, 50, or 100 jobs per run); compatible with keyword searches and locations.
- Multi-Level Extraction: Captures core job metadata and advanced details like descriptions and skills for full context.
- No-Code & Free to Use: Runs directly in your browser with a simple setup; no installation or coding required.
- Reliable Data Collection: Avoids blocks with a built-in IP management system, ensuring complete and uninterrupted scraping.
- Automation Integration: Connects with Make.com and n8n to schedule runs and auto-save data to Google Sheets.
- Flexible Data Export: Download collected data in standard, analysis-ready formats like CSV and JSON.
What Data Can You Scrape from Indeed?
With BrowserAct's Indeed Scraper, you can pull a wide range of publicly available data for analysis. Here's a breakdown:
Indeed Job Postings
- Job titles
- Company names
- Salary ranges
- Working locations
- Work arrangements (normalized to "Hybrid", "Remote", or "On-site")
- Tags (e.g., "Full-time, Contract", "401(k)", "Health insurance")
How to Use Indeed Scraper in One Click
If you want to quickly start experiencing scraping Indeed, simply use our pre-built "Indeed Job Scraper" template for instant setup and start scraping Indeed effortlessly.
- Register Account: Create a free BrowserAct account using your email.
- Configure Input Parameters: Fill in necessary inputs like Keyword (e.g., "software engineer"), Datalimit (e.g., 10), and Location (e.g., "New York, NY") – or use defaults to learn how to scrape Indeed quickly.
- Start Execution: Click "Start" to run the workflow.
- Download Data: Once complete, download the results file from Indeed scraping.

Why Scrape Indeed?
Scraping Indeed allows you to systematically collect and analyze public data from its job listings. This process is valuable for gathering specific information that can be used for business, research, and analysis. Here are the primary reasons to scrape Indeed:
- Gather Market Trends: Extract job postings to understand hiring patterns, in-demand skills, and salary benchmarks on specific topics or industries.
- Conduct Competitor Research: Collect data from rival companies' listings to identify recruitment strategies, offerings, and market positioning.
- Track Job Opportunities: Monitor postings in real-time to detect emerging roles, popular locations, and shifts in the job market before they become mainstream.
- Monitor Industry Mentions: Systematically find and log every mention of skills, companies, or trends to manage talent acquisition and analyze feedback.
- Build Datasets for Analysis: Create structured datasets from Indeed's public job data for use in machine learning, academic research, or detailed statistical analysis.
Scraping automates the data collection process, enabling you to efficiently gather large volumes of information from specific searches or locations for structured analysis.
How to Build an Indeed Scraper Workflow: Step by Step
Indeed Scraper workflow building with BrowserAct requires no coding skills—it's automation-ready and easy to set up. Follow these step-by-step instructions to get started.
Step 1: Start Node Parameter Settings
- Keyword: Set the job title, keywords, or company (e.g., "marketing").
- Datalimit: Set the number of jobs (e.g., 10).
- Location: Set the specific location or "remote" (e.g., "New York, NY").

Step 2: Add Visit Page Node
Add a "Visit Page" node and fill in the website URL as "https://www.indeed.com/". This will navigate to the Indeed homepage.

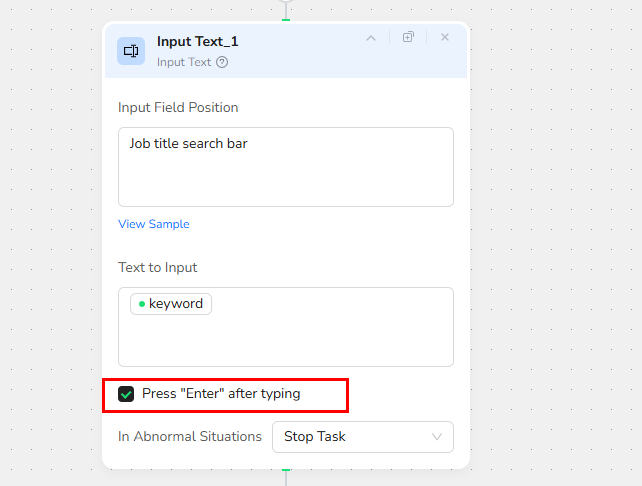
Step 3: Add Input Text Node
Add an "Input Text" node.
- In the "Input field position" field, write "Job title search bar" (this describes the position or specifies the input box).
- In the "Text to enter" field, write "/keyword" to select and input the keyword parameter.
Step 4: Add Click Element Node
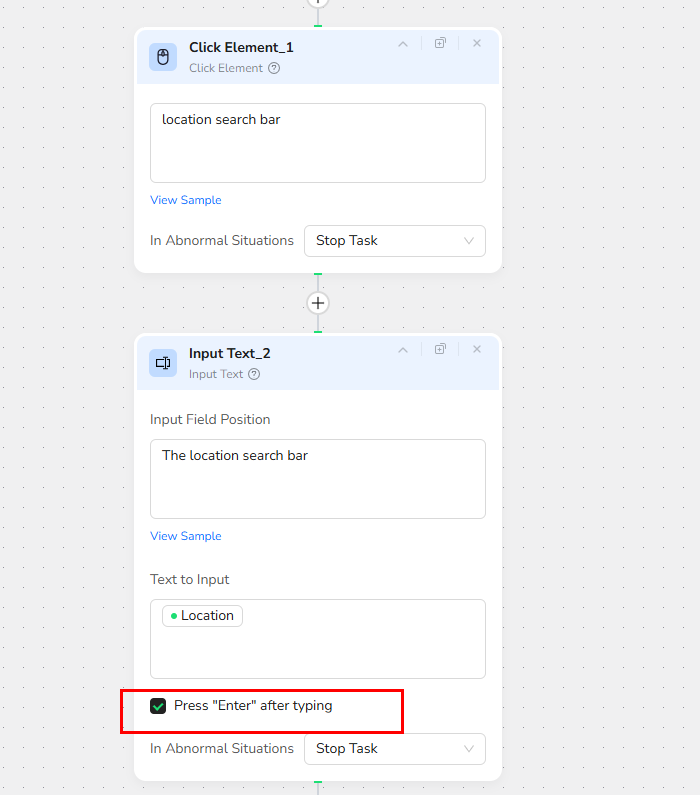
Add a "Click Element" node and input the prompt: "The location search bar"
Step 5: Add Input Text Node
Add another "Input Text" node.
- In the "Input field position" field, write "The location search bar".
- In the "Text to enter" field, write "/location" to select and input the location parameter.
Step 6: Add Click Element Node
Add a "Click Element" node and input the prompt: "Click the search button". This initiates the job search on Indeed.

Step 7: Add Scroll Page Node
Add a "Scroll Page" node and select "Scroll to bottom". This ensures all job postings on the page are loaded.

Step8: Add Extract Data Node
Add an "Extract Data" node.
- In the "Data Field" prompt box, enter:
- "Extract all /datalimit job postings in this page for the following fields: Job Title, Company Name, Salary, Location, Work Arrangement (Hybrid/Remote/On-site), Tags (the gray pill-style badges under each job card, e.g., “Full-time”, “401(k)”, “Health insurance”), Job URL (direct link to the job posting)
- Formatting rules:
- Salary: keep the original notation as shown in the posting (e.g., “80k”, “$80,000–$85,000 a year”, “$40/hour”). Do not normalize or strip symbols.
- Location: "City, State/Province, Country". If fully remote, use "Remote".
- Work Arrangement: normalize to exactly one of "Hybrid", "Remote", or "On-site".
- Tags: comma-separated, Title Case, taken from the gray pill badges under the job card (e.g., “Full-time, 401(k), Health Insurance”).
- Missing data: use "N/A".
- Notes: If multiple links are present, output the primary job posting link that opens the detailed job view."
- Check the "Filtering Criteria" option and enter: "Include only jobs related to /keyword; exclude all others."

Step 10: Output Data
Select "CSV" as the output format and check "Output as a file" for easy downloading. You can also choose to export in JSON, XML, or Markdown (MD) formats.

Who Can Use Indeed Scraper?
Indeed Scraper is designed for anyone needing quick, reliable access to Indeed data. It's ideal for a variety of users, including:
- Recruiters and HR Professionals: Extract listings for talent acquisition, trend analysis, and salary benchmarking.
- Job Market Analysts and Researchers: Monitor discussions for labor market studies, skill tracking, and economic insights.
- Talent Acquisition Specialists: Gather data on competitors' postings to refine hiring strategies.
- Data Analysts and Consultants: Collect job data for reports, dashboards, and predictive modeling.
- Small Businesses and Startups: Conduct affordable market research without needing advanced technical skills.
- Job Seekers and Career Coaches: Explore opportunities, track trends, or archive listings for personal projects.
No matter your background, if you're looking to scrape Indeed without hassle, this tool is accessible and effective for both individuals and teams.
Is It Legal to Scrape Indeed?
Yes, scraping publicly available data from Indeed is generally considered legal, provided it is done ethically and respects the platform's rules. This means only accessing information that is visible to any public visitor (like job postings and details), never attempting to access private data, and adhering to Indeed's Terms of Service to avoid overwhelming their servers with excessive requests. The way you use the data is also critical; it should not be used to violate copyright or privacy laws like GDPR or CCPA. Our Indeed Scraper is designed to operate within these responsible guidelines, focusing on ethical data extraction. Please note that this information does not constitute legal advice, and we recommend consulting with a legal professional to ensure full compliance for your specific project.
How Many Results Can You Scrape?
Our Indeed Scraper offers complete flexibility, giving you full control over the scale of your data extraction. By default, it is set to capture up to 10 jobs, which is ideal for quick sampling and testing. Since this scraper does not include pagination handling by default, it typically extracts a maximum of around 15 jobs from a single page. However, you can customize it yourself—BrowserAct fully supports pagination for scraping, allowing you to extract without any upper limits by adding page-turning actions. Ultimately, there are no hard limits when pagination is enabled; the tool is built to scale with your needs.
Just keep in mind that scraping a larger volume of data will naturally require more time to run and will consume more of your platform credits.
Make.com Integration
BrowserAct's Indeed Scraper is now available as a native app on Make.com—add it to your scenarios without API hassle.
- Automation-Ready: Integrate with Make, n8n, or others for scheduled monitoring.
- Rate Limit Handling: Built-in delays to comply with Indeed policies.
- Multi-Topic Tracking: Run instances for different keywords/locations.
💡 Use Case Tip: Ideal for job market analysis, trend tracking, and recruitment research with full posting context and details.
🚀 Quick Start with Make.com: Search for "BrowserAct" in Make.com's app directory and add it directly—no complex setup.
Need help? Contact us at
- 📧 Discord: [Discord Community]
- 💬 E-mail: service@browseract.com