
Website Data Scrape
Automatically extract website content and generate high-quality Facebook posts. Get structured JSON data to boost efficiency and automation.

Brief
Automatically Extract Updated Content from Any Webpage and Generate Facebook Posts
Use Cases:
New Product Launch Information Collection
Latest News Updates Collection
Market Trend Prediction
Workflow Steps:
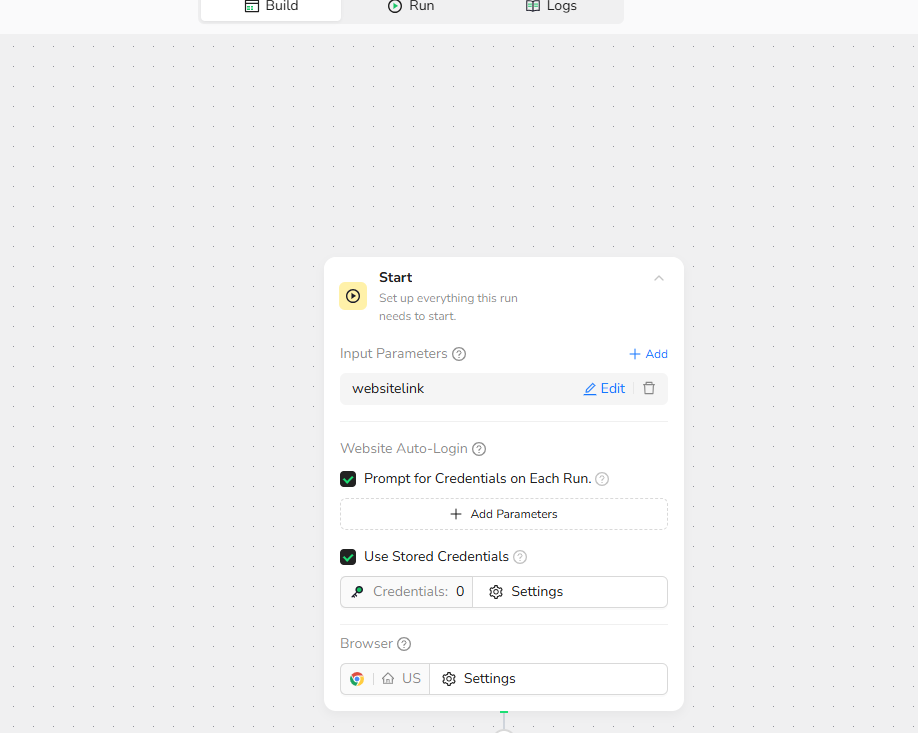
1.Start Node - Set the URL of target webpages and browser scraping parameters:
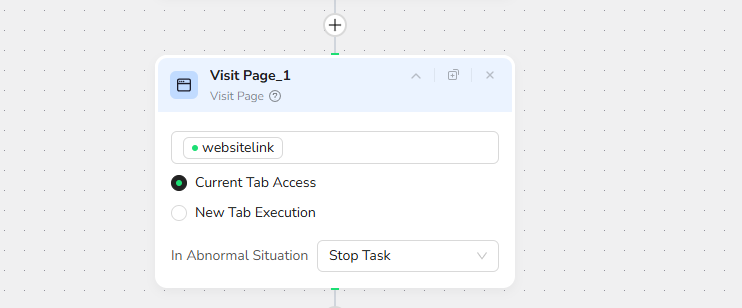
2.Visit Page
Visit target Website link pages automatically
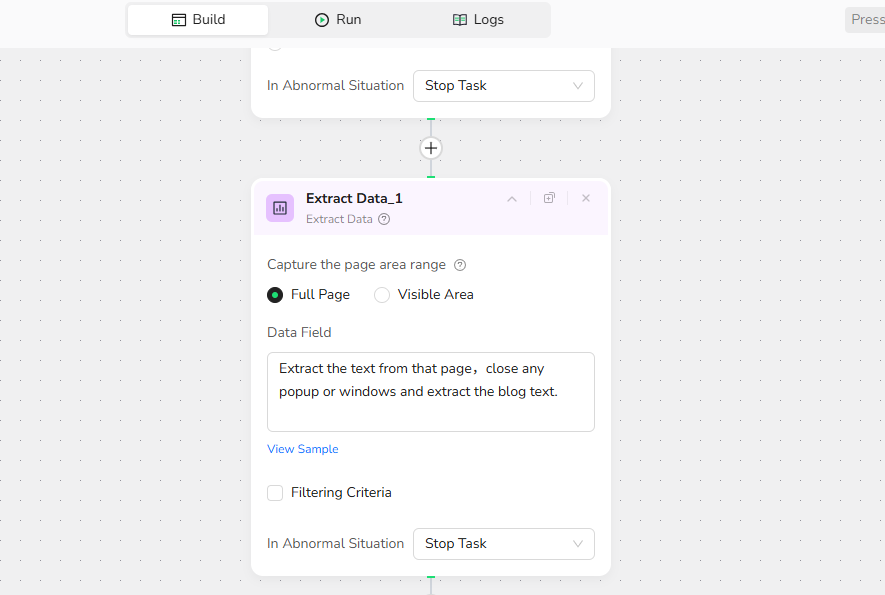
3.Extract Data
Scrape the text data from the pages, including titles, dates, author names, and main content.
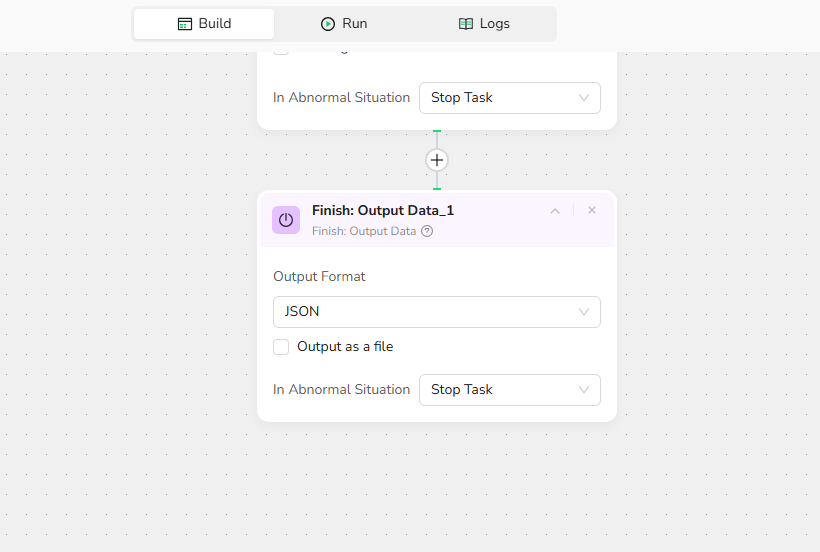
Export - Output the extracted information in JSON format for further analysis or integration.
Technical Integration
API Integration with Make
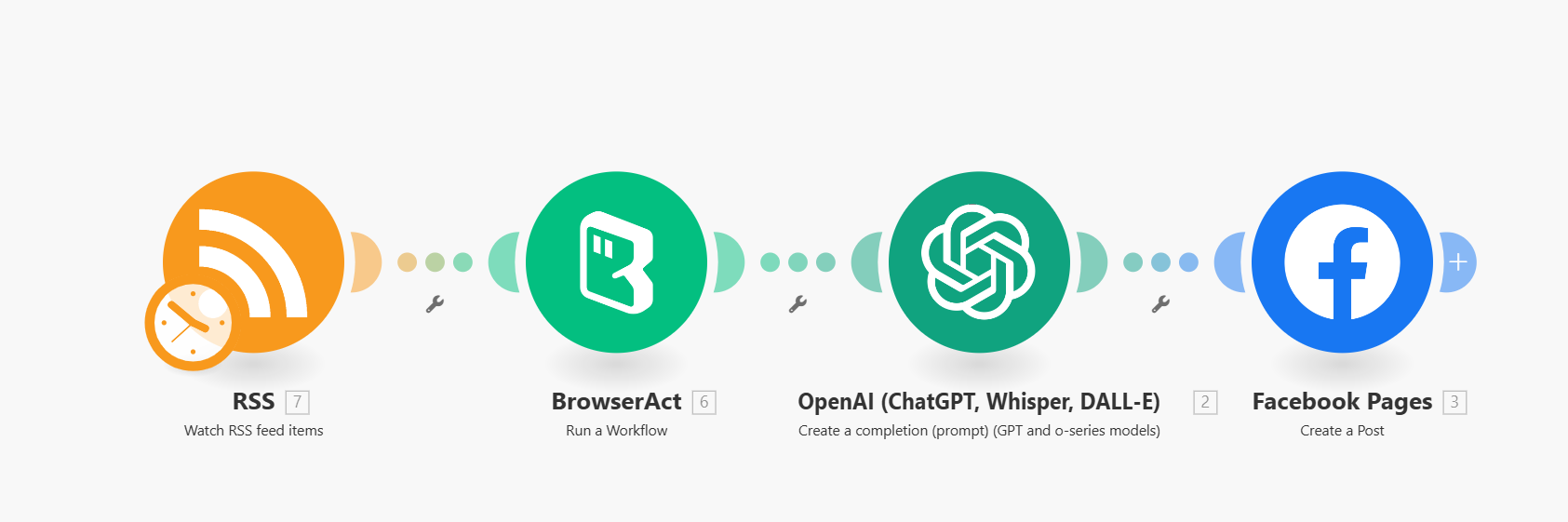
This workflow is specifically designed to integrate with Make to work alongside the “Automate Content Updates: Summarize RSS Feeds and Create Facebook Posts with ChatGPT and BrowserAct” system. Together, they create a fully automated solution for extracting and posting Facebook content.
Recommended Make Workflow Pattern
- RSS :Use an RSS node to track updates on target websites.
- Webiste Data Scrape:Automatically extract the latest content text and other relevant fields.
- OpenAl: Summarize the extracted content and generate high-quality social media posts.
- Facebook Pages:Automatically create and publish posts on your Facebook page.
Complete Automation Workflow
RSS →Website Data Scrape → OpenAl → Facebook Pages
Ready to Automate Your Web Data Scraping Tasks?
Start your automated workflow in just a few minutes!
Need Help?
Contact us at:
• Discord: Join our community
• E-mail: service@browseract.com