Twitter/X Content Aggregation
With X (formerly Twitter), the world’s leading real-time social media and information dissemination platform, booming—are you wasting countless hours manually collecting social media information such as tweet content, post time, interaction metrics (likes, retweets, comments, quote tweets), user profiles (follower count, bio, verification status), trending hashtag rankings, and brand mention frequency? Faced with X’s massive repository of real-time content (spanning millions of tweets, paginated search results, and dynamic trend lists), efficiently acquiring structured social data to accurately track public opinion trends, optimize brand communication strategies (for marketers) or enhance hot-topic capture efficiency (for journalists) has become a common challenge for many brand marketing professionals, public opinion analysts, market researchers, journalists, and social media operators. Say goodbye to tedious manual copy-and-paste and page-by-page recording of interaction data or trend changes. BrowserAct will revolutionize the way you access X’s social media intelligence.
What is BrowserAct Financial Data Automation Scraper ?
BrowserAct is a powerful automated data extraction tool that allows you to easily scrape required data from any web page without programming knowledge. It can efficiently capture key social media data from X’s (formerly Twitter) massive repository of real-time content, including tweets, user profiles, and trend lists. What can it do for you?
- X (Twitter) Social Data Scraping: Our X crawler can intelligently identify and extract core social media data from the platform, including tweet content (text, embedded links/hashtags), post timestamp (with time zone), interaction metrics (likes, retweets, comments, quote tweets), user profiles (username, follower count, verification badge status, bio content), trending hashtag rankings (topic name, tweet volume), and brand/keyword mention frequency (e.g., how often a product is cited in related posts).
- AI-Powered Field Suggestions: Using AI to intelligently identify the structure of X’s pages (e.g., search result feeds, user profile timelines, trending topic sections), it quickly suggests and extracts key fields such as "tweet content, post time, interaction count, username, trending hashtag". No manual positioning is needed, and structured data is generated directly to support efficient analysis.
- Ideal Users: Suitable for brand marketing professionals, public opinion analysts, journalists, social media operators, and market research teams. It helps you obtain structured X social data to drive decisions (such as optimizing brand communication strategies, adjusting social media campaigns) or meet research needs (like monitoring public opinion trends, tracking the spread of hot topics, analyzing user feedback on products).
Features and Workflow Capabilities
- Input Parameters for Effective Conecte Imóvel Scraping. Detailed explanation of required input parameters, presented in a table for clarity:
Parameter | Required | Description | Example Value |
Targeted_Link | Yes | The base URL of the X site to start scraping from. | https://x.com/home |
Targeted_Hour | Yes | from 6 hours ago till now | |
Username | Yes | ||
PhoneNumber | Yes | ||
Password | Yes |
How to Use BrowserAct as a CoinMarketCap Scraper
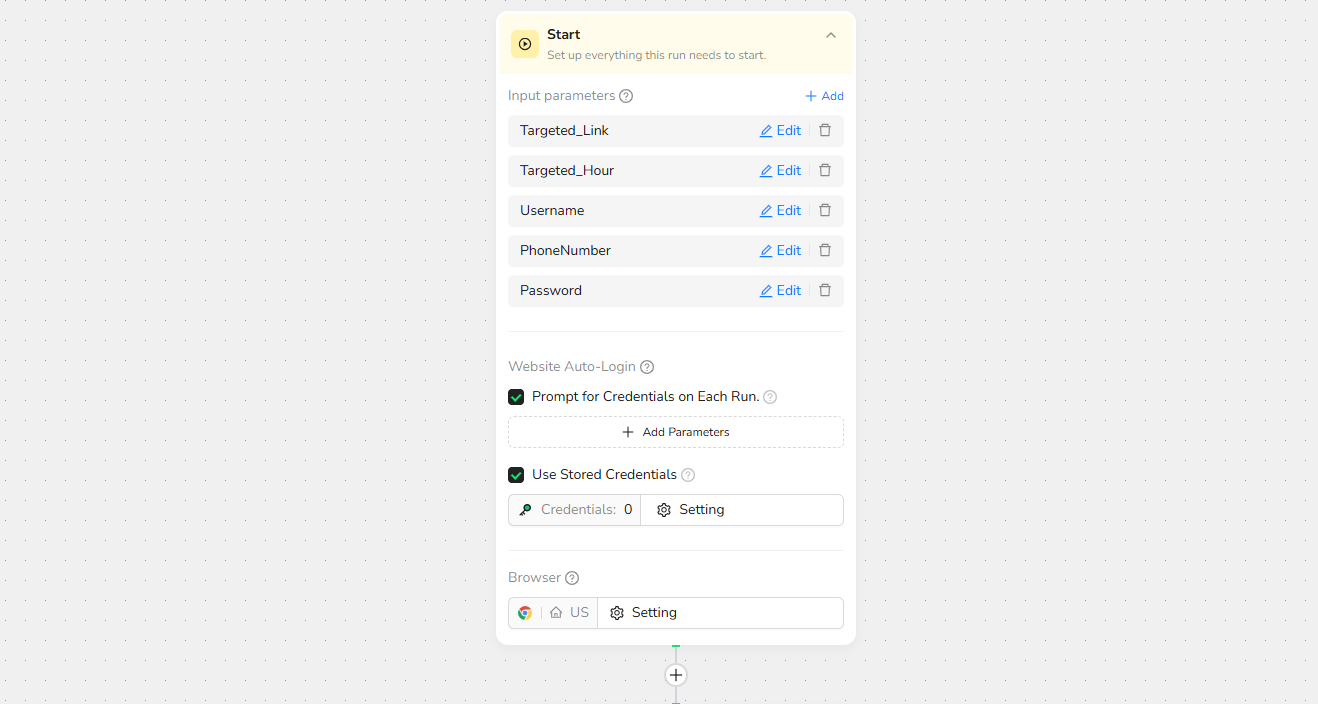
Step 1: Create Workflow and Set Input Parameters
- Click the "Workflow" button in the left sidebar, then "Create" to name your workflow (e.g., "Financial Data Automation").
- Define customizable inputs for flexibility:
Targeted_Link
Targeted_Hour
Username
PhoneNumber
Password
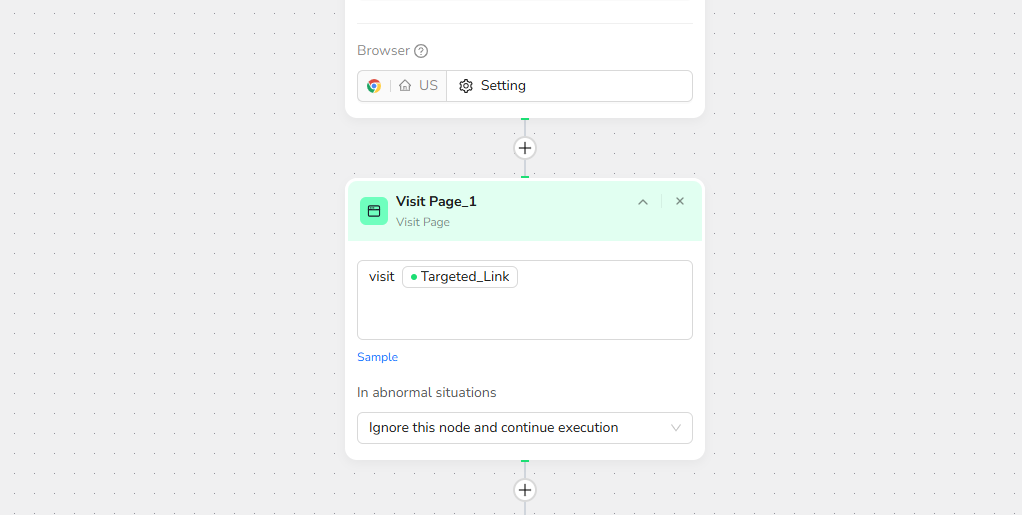
Step 2: Add Navigation and Search Actions 📍
- Click the "+" icon to add actions. Start with "Visit Page" and enter "Visit /url" to direct the workflow to the specified URL, such as https://x.com/home . BrowserAct's AI will automatically understand the page structure, powering your Forbes web scraper without hassle.
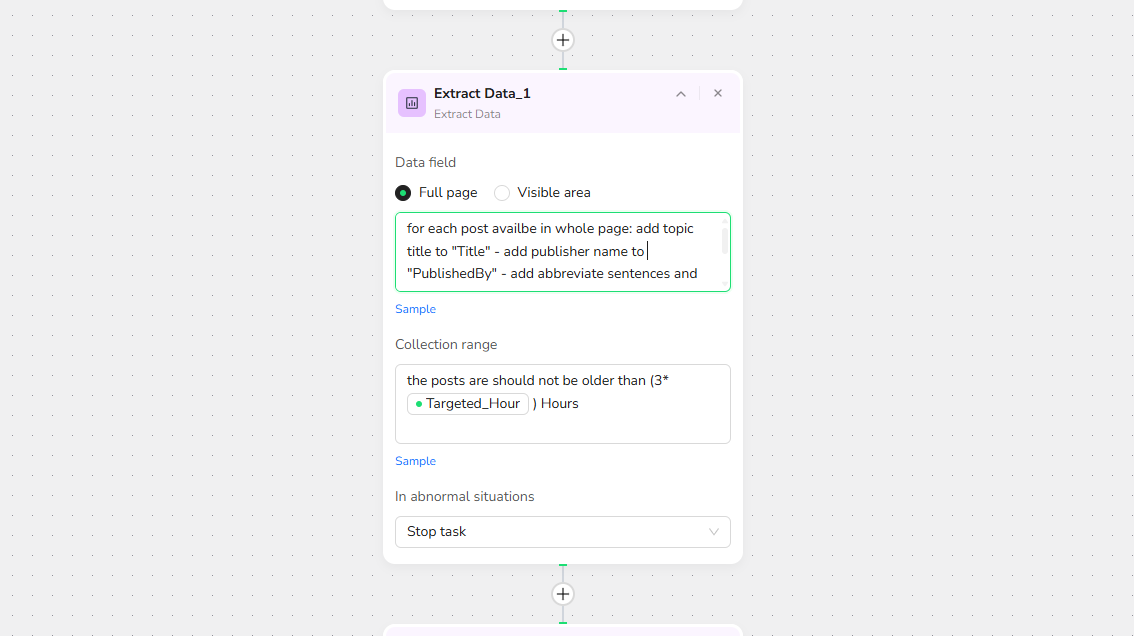
Step 3: Add "Extract Data" Action 📊
- Click "+" and select "Extract Data." In the description box, specify what to extract and set limits, such as:
for each post availbe in whole page: add topic title to "Title" - add publisher name to "PublishedBy" - add abbreviate sentences and summary to "Summary" - add the post link to "Url" - Extract the picture link to "Pic" if the post has no picture just add "no picture" to the "Pic"
- The AI will interpret your request and precisely scrape Rightmove houses list—no CSS selectors, no XPath, no coding required. This makes BrowserAct a seamless job scraper for scraping jobs from the internet.
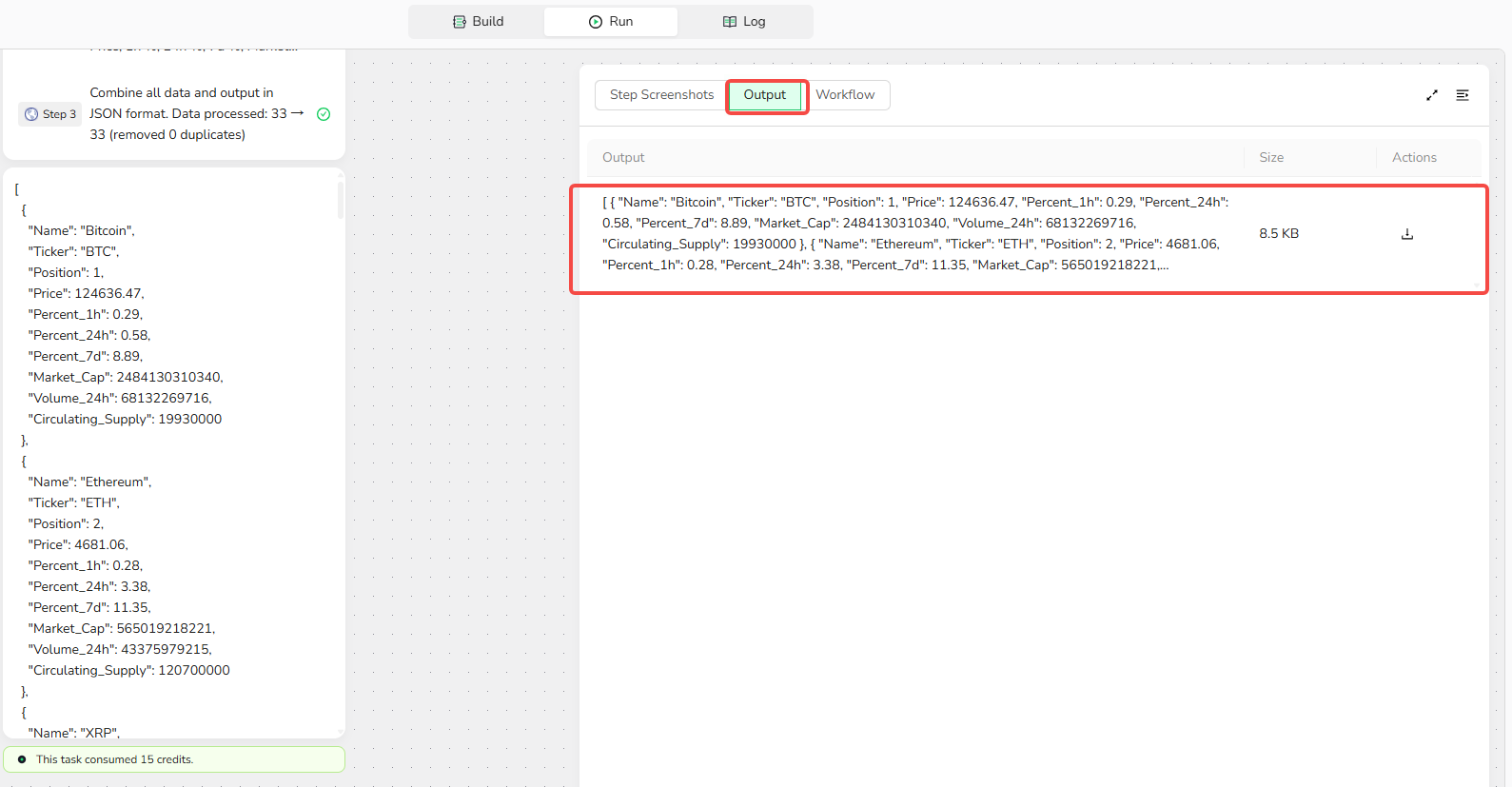
Step 4: Add Output, Publish, and Run 📈
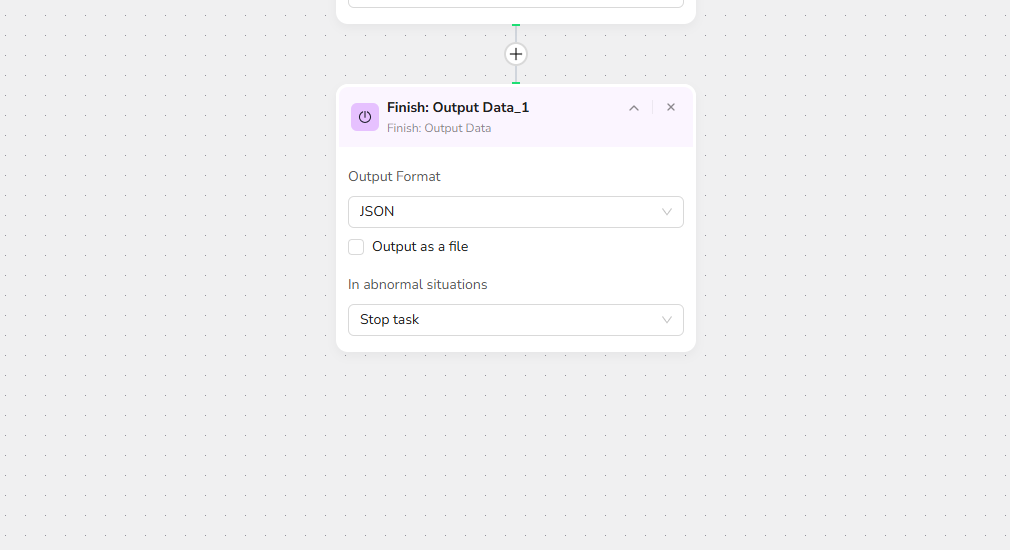
- Click "+" and select "Finish: Output Data." Choose CSV as the output format and enable "Output as a file" for easy downloading.
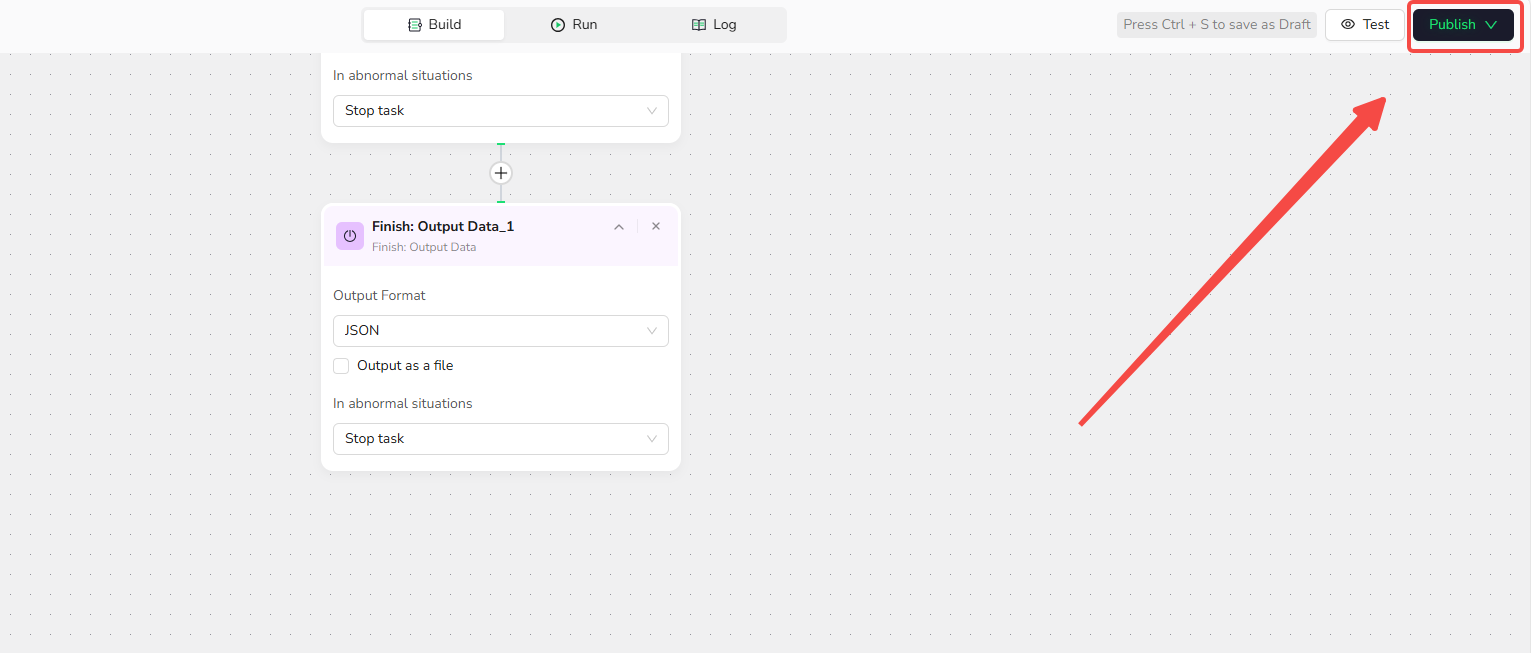
- Click "Publish" to save and finalize your Forbes scraper.
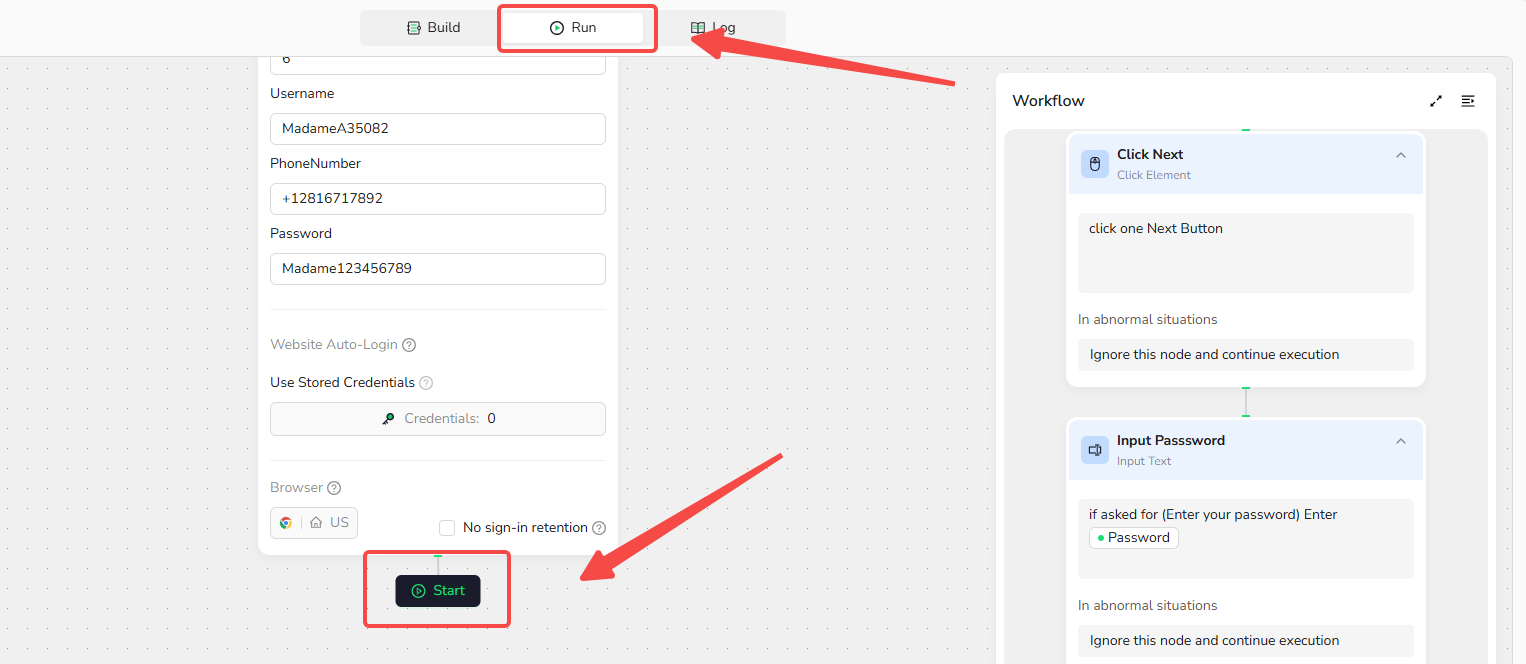
- Navigate to the "Run" section. Adjust parameters if Forbes (or use defaults), then click "Start" to execute the scrape.
Step 5: Download the Results
- Before downloading, you can preview the scraped results to see if they meet your expectations.