
Reddit Content Scraper: Automated Post Data Collection

Brief
Automatically extracts Reddit post data, including titles, content, engagement metrics, and comment counts from any subreddit or thread, with flexible filtering and output options for seamless integration.
Use Cases:
- Monitor brand mentions and trending discussions across Reddit communities
- Track post performance and engagement metrics (upvotes, comments, awards)
- Conduct market research by analyzing popular posts in relevant subreddits
- Identify trending topics and viral content for content marketing strategies
- Collect competitive intelligence by monitoring industry-related subreddits
- Build datasets for sentiment analysis and social listening at scale
- Research community opinions and emerging trends for business intelligence
Workflow Steps:
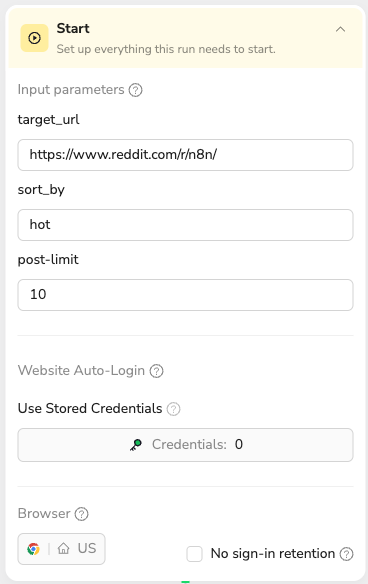
1.Start & Configure Parameters
- Set up three input parameters: target_url (Reddit page URL like "https://www.reddit.com/r/n8n/"), sort_by (sorting option: hot, new, top, rising), and post_limit (number of posts to extract, e.g., "10")
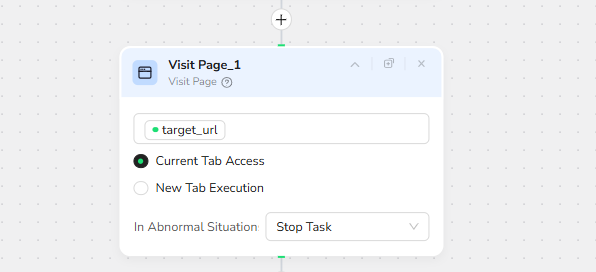
2.Visit Target Page
- Navigates to the specified Reddit URL with the target_url parameter
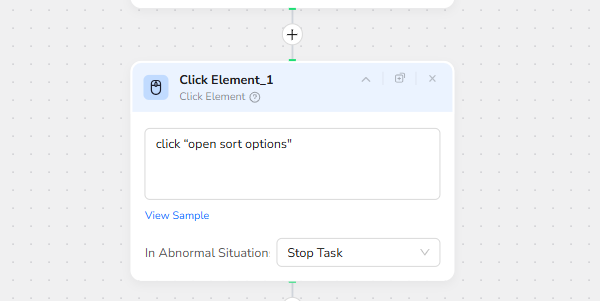
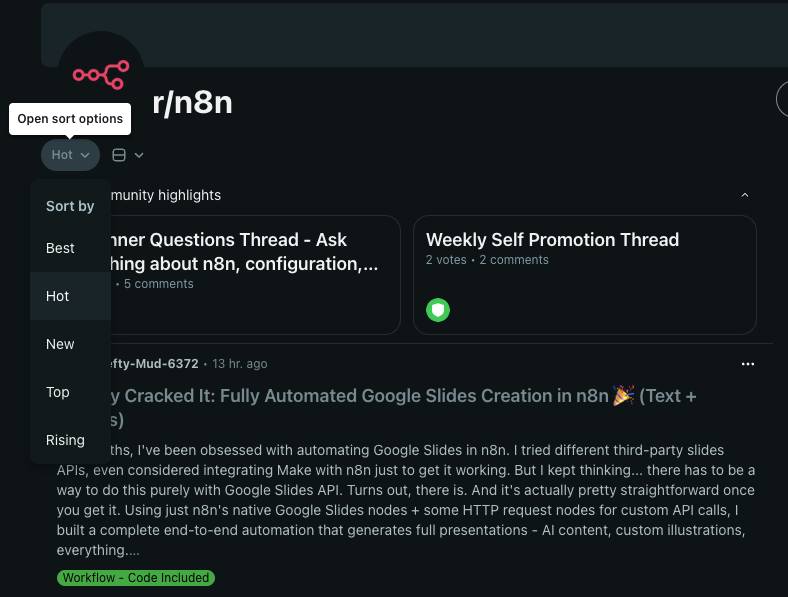
3.Click Element
- click “open sort options"
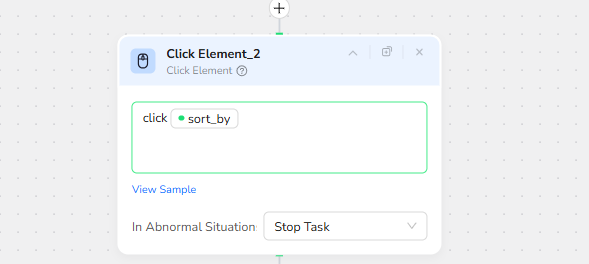
4.Click Element
click /sort_by
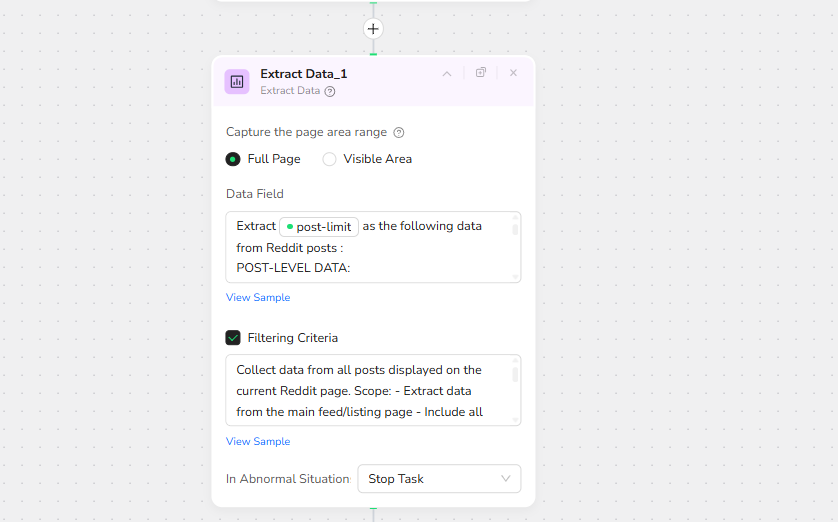
5.Extract Data
Extract /post-limit as the following data from Reddit posts :
POST-LEVEL DATA:
1. Post Creator (username with u/ prefix)
2. Subreddit Name (community name with r/ prefix)
3. Post Title (complete headline text)
4. Post Content (full body text of the post)
5. Post Flair/Tag (category label if available)
6. Upvotes Count (total upvotes number)
7. Comments Count (total number of comments)
8. Post URL (direct link to the post)
9. Post Timestamp (time posted, e.g., "13 hr. ago" or exact date)
10. Top Comments
11. Awards Count
12. Post Type (text, image, video, link, poll)
6.Finish & Output Data
Returns extracted data in your preferred format (JSON, CSV, XML, or Markdown) containing structured post information with engagement metrics
Key Features:
- Customizable Parameters: Adjust target_url, sort_by, and post_limit to match your specific research needs
- Flexible Sorting Options: Choose from hot, new, top, or rising to capture different content perspectives
- Engagement Metrics: Track upvotes, comment counts, and awards to identify high-performing content
- Content Preservation: Extracts full post text, links, and formatting for complete data capture
- Make.com Integration: Browseract is now available as a native app on Make.com - simply add it to your scenarios without complex API setup
- Automation-Ready: Easily integrate with Make, n8n, or other automation platforms for scheduled data collection
- Rate Limit Handling: Built-in delays and error handling to respect Reddit's usage policies
- Multi-Subreddit Support: Run multiple instances to track different communities simultaneously
Data Extraction Scope:
- ✅ Extracts: Post titles, content, authors, upvotes, comment counts, awards, timestamps, URLs, flairs, and post types
- ❌ Does not extract: Individual comment text or nested comment threads (only total comment count per post)
- 💡 Use Case: Perfect for post-level analysis, trend identification, and engagement tracking without deep-diving into comment threads
Ready to automate? Try this workflow now →
🚀 Quick Start with Make.com: Browseract is now available as an official app on Make.com! Simply search for "Browseract" in the Make.com app directory and add it directly to your automation scenarios - no complex configuration needed.
Need help? Contact us at
- Discord: [Discord Community]
- E-mail: service@browseract.com