
Movie Article Builder - IMDb

Brief
🎯 Core Function: Deep Data Extraction & Automated Blogging
This workflow is a sophisticated "Research-to-Publish" engine. It automates the complex navigation of IMDb to harvest three distinct layers of data: Core Movie Details, Technical FAQs, and User Reviews. It then pipes this rich dataset into Gemini AI to generate a fully styled, mobile-responsive HTML article, ready to be pasted directly into WordPress or any CMS.
Part 1: BrowserAct Workflow Description
This core module performs human-like navigation to gather data from multiple sections of IMDb:
Precise Search & Entry:
The workflow accepts two simple inputs: Movie and Year.
It constructs a specific IMDb search query (/find?q=...) and intelligently clicks the first result that matches your keyword, ensuring it lands on the correct movie page.
Layer 1: Core Metadata & Visuals:
On the main page, the Agent extracts the "Hero" data: Director, Writer, Stars, Storyline/Synopsis, and high-quality image URLs from the Photos section.
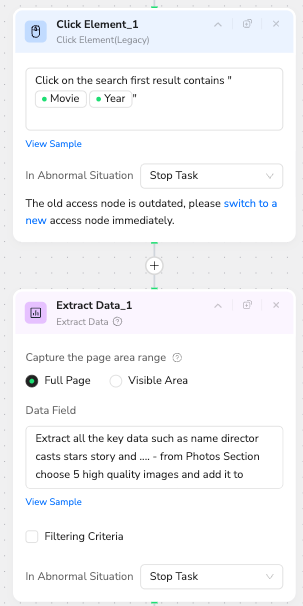
Layer 2: Technical Facts (FAQ Navigation):
The Agent clicks into the "FAQ" section. Here, it scrapes Q&A objects to gather specific details often missed by simple scrapers (e.g., Runtime, Budget, release specificities, or plot explanations).
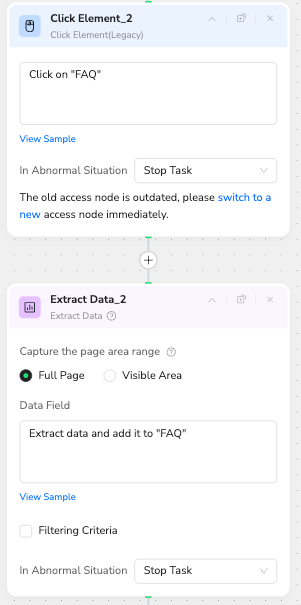
Layer 3: Audience Sentiment (Review Loop):
The Agent executes a "Go Back" action to return to the main hub, then navigates specifically to the "User Reviews" tab.
It extracts a structured list of User Names and Review Texts, filtering out duplicates to ensure a clean dataset.
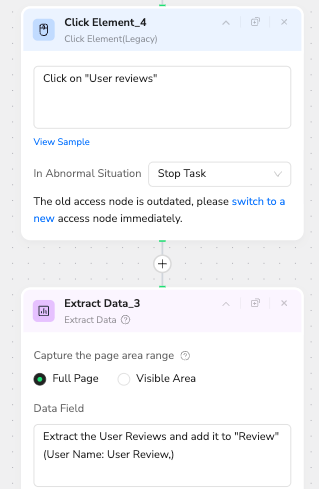
Consolidated Output:
All extracted data points are merged into a comprehensive JSON object and sent to Make.com.
Part 2: Automation Integration with Make.com
The Make.com scenario acts as the "Editor-in-Chief," processing the raw data into a polished product:
Batch Processing Trigger: The workflow connects to a Google Sheet containing a list of movies. An Iterator module processes them one by one, allowing you to generate hundreds of articles in a single run.
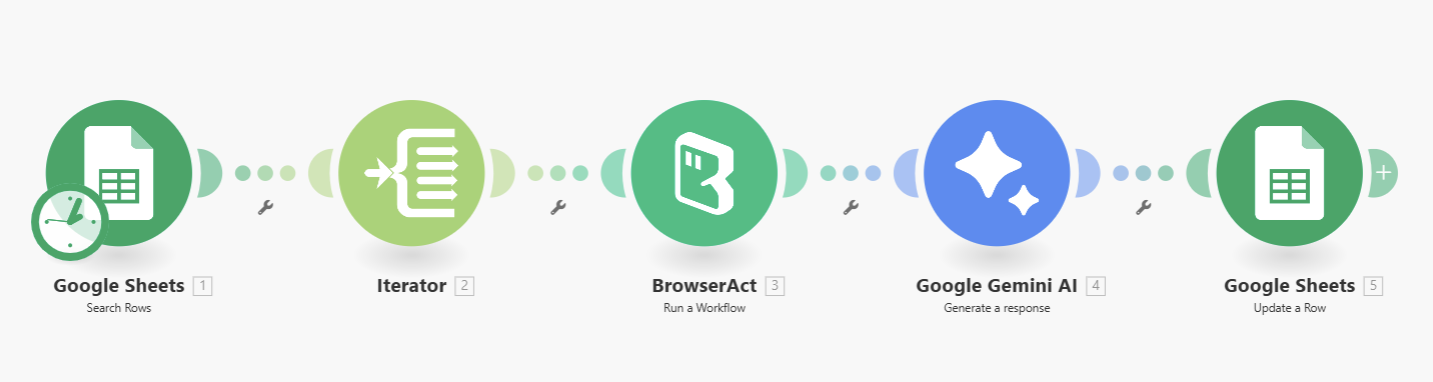
AI Article Synthesis (Gemini): The raw JSON is sent to Gemini with a highly specific System Prompt. The AI is instructed to:
Structure: Create a semantic HTML5 document (Headings, Tables, Blockquotes).
Style: Inject CSS for a clean, modern look (Responsive grid for images, styled "Movie Details" table).
Filter: Automatically remove reviews containing "Spoiler" warnings to keep the article safe for new viewers.
Final Delivery: The result is a complete HTML string stored back into your Google Sheet. You simply copy this cell and paste it into your website's "HTML/Code" view to publish.
✨ Applicable Scenarios (Use Cases)
Niche Movie Blogs: Automatically populate a review site with detailed, SEO-rich articles about trending or classic films without writing a single word.
SEO Content Farms: Generate high-quality, long-form content (2000+ words via reviews and FAQs) that targets specific movie keywords.
Database Enrichment: Use the "FAQ" and "Core Data" extraction to build a proprietary database of movie metadata for apps or analysis.
Sentiment Analysis: Aggregate thousands of user reviews into a spreadsheet to analyze audience reaction trends for specific genres or actors.