
Automating Daily Instagram Feed Summary & AI analyze in a Telegram Channel(Login required)
BrowserAct’s no-code tool automates daily Instagram feed summaries—AI analyzes content, distills key insights, and pushes results to your Telegram channel fast!

Brief
Are you spending hours manually collecting Instagram profile data—usernames, bios, post details, followers, stories, and more? With millions of users, posts, and media to browse through, finding the right data or conducting research has become incredibly time-consuming for influencers, marketers, analysts, and social media managers.
BrowserAct automates the entire process. Extract structured data from Instagram in minutes, not hours—no coding required.
What Does BrowserAct Instagram Scraper Do?
Automatically extract comprehensive Instagram resource data with our powerful Instagram scraper tool. Capture profile usernames, bios, post captions, like counts, comment counts, follower/following numbers, story highlights, and links to profiles from any Instagram page. Enjoy flexible filtering and output options for comprehensive market analysis—no coding required.
Our Instagram scraper is built for seamless integration with automation platforms like Make.com, making it ideal for ongoing monitoring and competitive intelligence tasks.
What Data Can I Extract from Instagram?
With BrowserAct's Instagram Scraper, you can pull a wide range of publicly available data for analysis. Here's a breakdown:
Instagram Profiles & Features
- Usernames and handles
- Bios and descriptions
- Post captions and content
- Like and view counts
- Comment counts
- Follower and following numbers
- Story highlights and reels
- URLs and links to profiles/posts
Key Features of Instagram Scraper
- Customizable Parameters: Adjust extraction scope to match your research needs
- Flexible Selection: Set max items for bulk extraction across multiple pages
- Comprehensive Data Capture: Extracts complete profile data with all metadata
- Structured Output: Preserves data relationships for easy analysis
- Multi-Page Support: Compatible with profile feeds, search results, and story views
- Automation-Ready: Seamlessly integrates with Make.com and other platforms
How to Scrape Instagram
Quick Start Guide: How to Use Instagram Scraper in One Click
If you want to quickly start experiencing scraping Instagram, simply use our pre-built "Instagram Scraper" template for instant setup and start scraping Instagram effortlessly.
- Register Account: Create a free BrowserAct account using your email
- Configure Parameters: Fill in necessary inputs like Target_url (e.g., "https://www.instagram.com/explore/search?keyword=example") – or use defaults to learn how to scrape Instagram quickly
- Start Execution: Click "Start" to run the workflow
- Download Data: Once complete, download the results file from Instagram scraping
How to Build a Instagram Scraper Workflow: Step by Step
Instagram Scraper workflow building with BrowserAct requires no coding skills—it's automation-ready and easy to set up. Follow these step-by-step instructions to get started.
- Determine Your Scope
Decide the number of results to extract (e.g., 50 results with complete details). Adjust parameters based on your research needs.
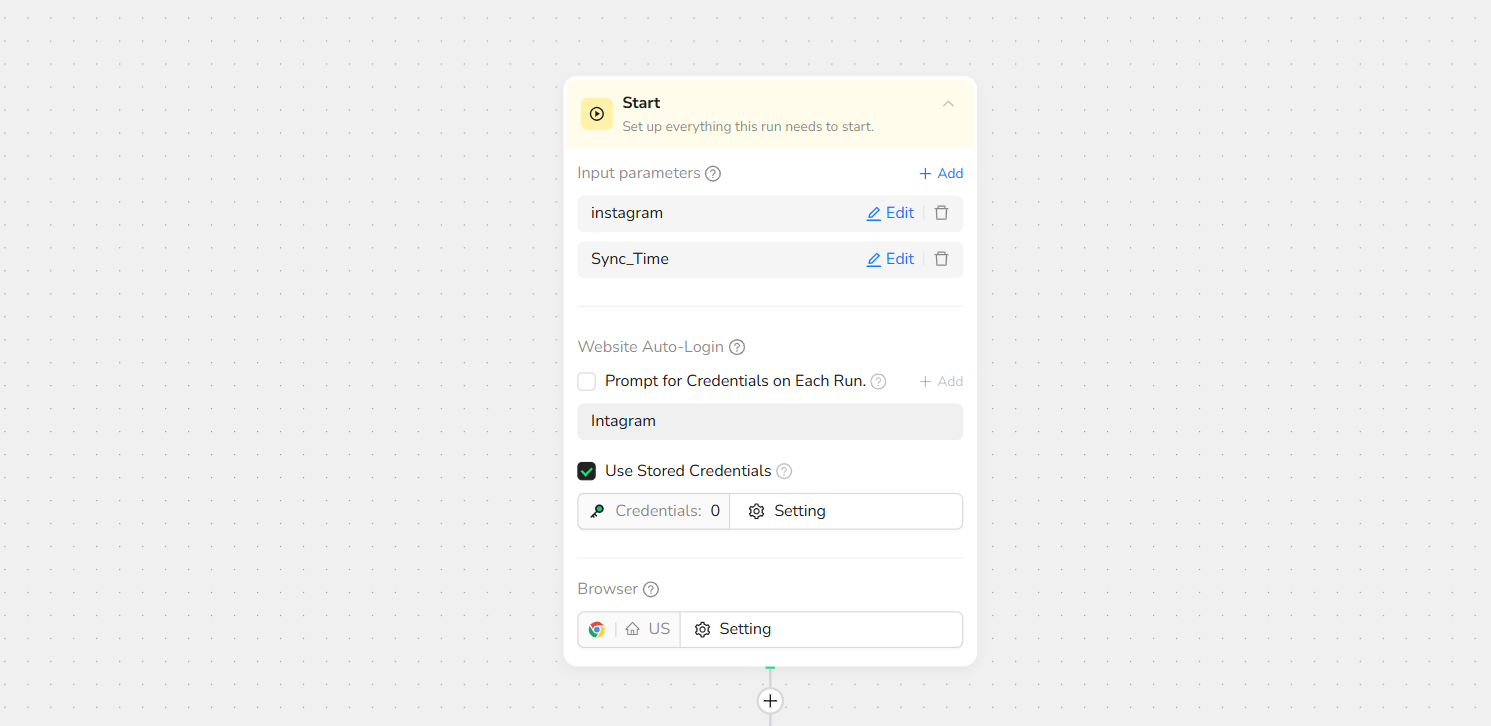
- Start Node Parameter Settings
- instagram: Enter your Instagram link (e.g., https://www.instagram.com/)
Note: Customize based on needs—works with profile feeds, search results, or story views.
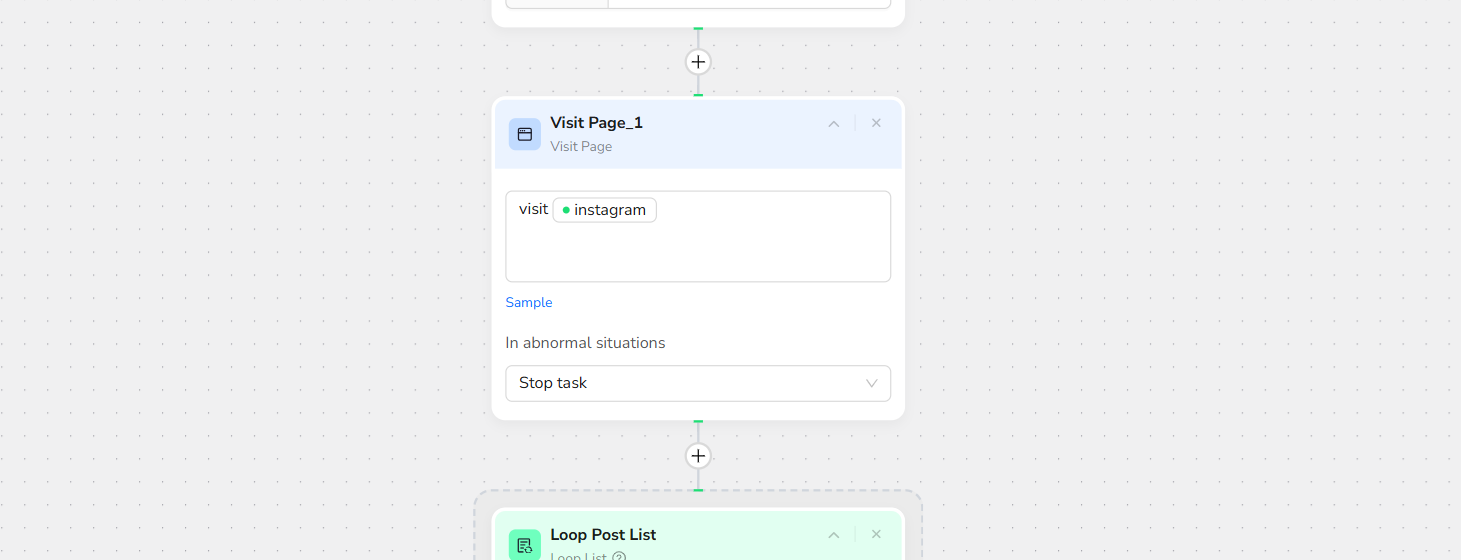
- Visit Page
In the prompt box, enter Visit / instagram – this will navigate to the target URL.
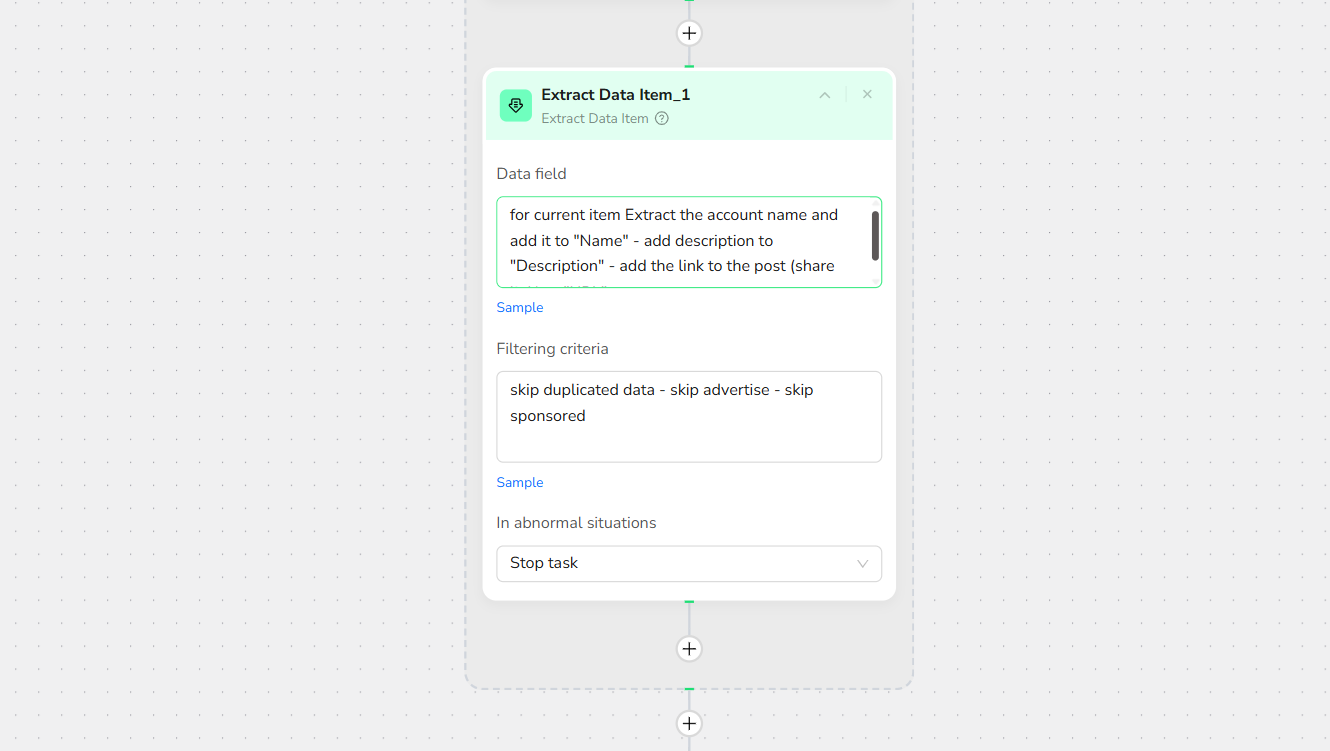
- Add Extract Data
In the prompt box, enter:
for current item Extract the account name and add it to "Name"
- add description to "Description"
- add the link to the post (share link) to "URL"
Note: You can specify the exact location of the data to be collected on the page to increase the accuracy of data extraction.
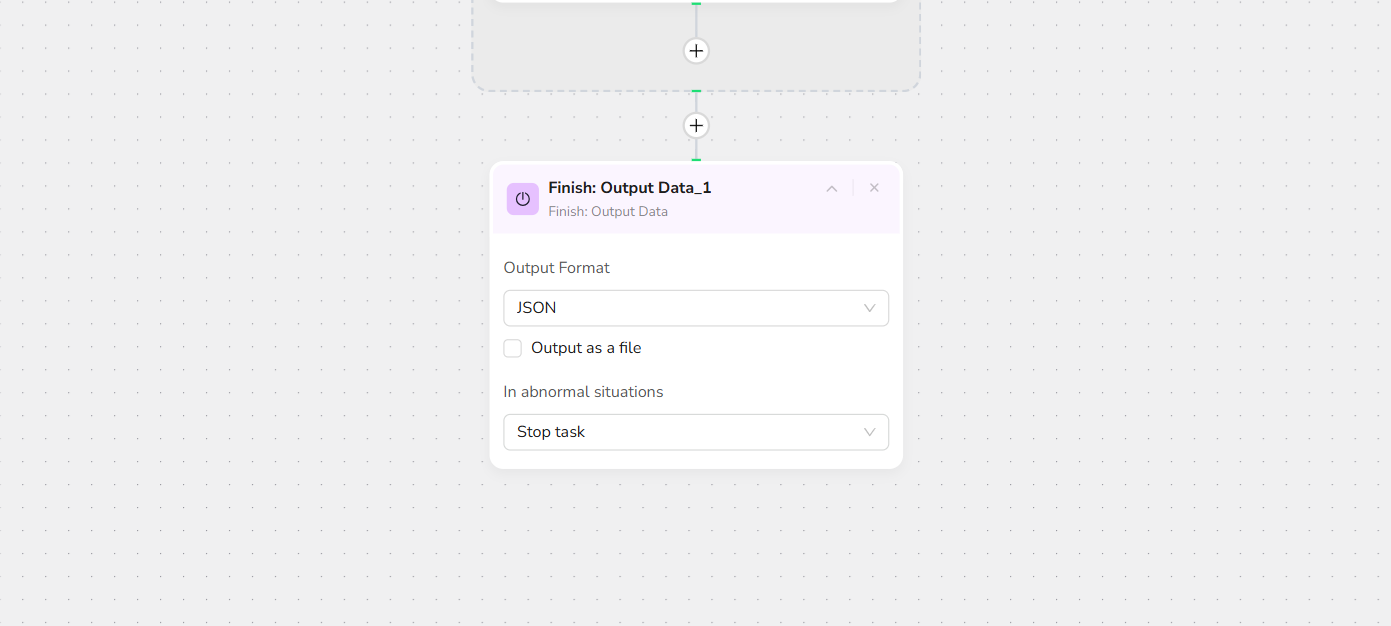
- Output Data
Export in JSON, CSV, XML, or Excel formats.
Key Benefits of Instagram Scraper
Instagram Scraper offers a range of advantages that make data extraction simple, efficient, and powerful. Here's why it's a top choice for Instagram web scraping:
✅ No Coding Required: Set up and run extractions effortlessly without any programming skills—perfect for beginners and pros alike
✅ Customizable and Flexible: Adjust parameters like item limits, data fields, and target URLs to tailor results to your exact needs
✅ Structured Data Output: Maintains organized data in structured formats (e.g., JSON, CSV, Excel) for easy analysis and integration
✅ Automation Integration: Seamlessly works with Make, n8n, and other platforms for scheduled, hands-off web scraping
✅ Cost-Effective: Start with free trials for small-scale tasks, scaling affordably for larger datasets while respecting Instagram's policies
✅ Accurate and Reliable: Handles automatic page loading, uses 'N/A' for missing data, and includes rate limit handling to ensure consistent results
These benefits make Instagram Scraper an efficient tool for turning raw Instagram data into actionable insights.
Who Can Use Instagram Scraper?
Instagram Scraper is designed for anyone needing quick, reliable access to Instagram data. It's ideal for a variety of users, including:
- Influencers & Creators: Track engagement trends and audience growth
- Marketers & Social Media Managers: Analyze content performance and identify viral strategies
- Brand Analysts: Conduct competitive analysis and monitor hashtag usage
- Digital Agencies: Manage client campaigns with comprehensive profile data
- Market Researchers & Analysts: Extract data for trend analysis and market intelligence
- E-commerce Teams: Gather insights on product promotions and user feedback
- Small Businesses & Startups: Conduct affordable competitive research without needing advanced technical skills
- Academics & Students: Research social media trends and user behavior ecosystems
No matter your background, if you're looking to scrape Instagram without hassle, this tool is accessible and effective for both individuals and teams.
Use Cases for Instagram Scraper
Instagram Scraper is versatile for various real-world applications. Here are some key ways to use it for extracting and analyzing Instagram data:
📊 Market Research: Collect data on posts, stories, and trends for informed decision-making
🔍 Competitive Intelligence: Scrape competitor profiles to identify strengths, weaknesses, and content opportunities
💰 Campaign Analysis: Track engagement metrics and compare performance across similar accounts
⭐ Quality Assessment: Analyze likes, comments, and views to identify top-performing content
🔄 Update Monitoring: Track post frequencies and story updates
🛠️ Content Selection: Build comprehensive comparison databases to curate the best ideas for your feeds
📈 Trend Tracking: Monitor emerging hashtags and popular niches in the Instagram ecosystem
🎯 Influencer Research: Identify reliable creators and assess their portfolios
Whether for one-off projects or ongoing monitoring, Instagram Scraper helps transform Instagram data into valuable insights.
Make.com Integration
BrowserAct's Instagram Scraper is now available as a native app on Make.com—add it to your scenarios without API hassle.
✅ Automation-Ready: Integrate with Make, n8n, or others for scheduled monitoring
✅ Rate Limit Handling: Built-in delays to comply with Instagram policies
✅ Multi-Profile Tracking: Run instances for different accounts, hashtags, or locations
💡 Use Case Tip: Ideal for competitive analysis, engagement tracking, and market research with complete profile metadata
🚀 Quick Start with Make.com: Search for "BrowserAct" in Make.com's app directory and add it directly—no complex setup
Ready to Transform Your Instagram Data Collection?
Stop wasting hours on manual data collection. Start scraping Instagram profiles, posts, and trends in minutes with BrowserAct's AI-powered automation.
Try BrowserAct Free → https://www.browseract.com/
No credit card required. Get started in under 5 minutes.
Popular Use Cases:
- 🛍️ Influencers tracking growth metrics
- 💻 Marketers analyzing viral content
- 📊 Analysts monitoring hashtag trends
- 🏢 Agencies managing brand campaigns
- 🚀 Creators performing audience research
Start Your Free Trial → https://www.browseract.com/template?page=3
Need Help?
Contact us at:
- 📧 Discord: https://discord.com/invite/UpnCKd7GaU
- 💬 E-mail: service@browseract.com